Tutorial 19.1 - Git and version control
27 Jul 2018
- https://git-scm.com/book/en/v2
- https://www.atlassian.com/git/tutorials
- https://marklodato.github.io/visual-git-guide/index-en.html
- https://git-scm.com/docs/gittutorial
- https://marklodato.github.io/visual-git-guide/index-en.html
- https://try.github.io/levels/1/challenges/1
- https://onlywei.github.io/explain-git-with-d3/
- http://git-school.github.io/visualizing-git/
- https://github.com/sensorflo/git-draw
This tutorial will take a modular approach. The first section will provide an overview of the basic concepts of git. The second section will provide a quick overview of basic usage and the third and final section will cover intermediate level usage. In an attempt to ease understanding, the tutorial will blend together git commands and output, schematic diagrams and commentary in an attempt to ease understanding.
The following table surves as both a key and overview of the most common actions and git 'verbs'.
Initialize git
|
git init |
Establish a git repository (within the current path if no path provided) |
Staging
|
git add <file> where <file> is one or more files to stage |
Staging is indicating which files and their states are to be included in the next commit. |
Committing
|
git commit -m "<Commit message>" where <Commit message> is a message to accompany the commit |
Commiting generates a 'snapshot' of the file system. |
Checkout
|
git checkout "<commit>" where <commit> is a reference to a commit to be reviewed |
Explore the state associated with a specific commit |
Reset
|
git reset --hard "<commit>" where <commit> is a reference to a commit |
Return to a previous state, effectively erasing subsequent commits.. |
Revert
|
git revert "<commit>" where <commit> is a reference to a commit that should be nullified (inverted) |
Generate a new commit that reverses the changes introduced by a commit thereby effectively rolling back to a previous state (the one prior to the nominated commit) whilst still maintaining full commit history. |
Branching
|
git branch <name> git checkout <name> where <name> is a reference to a branch name (e.g. 'Feature') |
Take edits in the project in a new direction to allow for modifications that will not affect the main (master) branch. |
Merging
|
git checkout master git branch <name> where <name> is a reference to a branch name (e.g. 'Feature') that is to be merged back into master. |
Incorporate changes in a branch into another branch (typically master). |
Pulling
|
git pull -u <remote> <branch> where <remote> is the name of the remote (typically origin) and <branch> is the branch to sync with remote (typically master). |
Pull changes from a branch of a remote repository. |
Pushing
|
git push -u <remote> <branch> where <remote> is the name of the remote (typically origin) and <branch> is the branch to sync with remote (typically master). |
Push changes up to a branch of a remote repository. |
Context
Git is a distributed versioning system. This means that the complete contents and history of a repository (in simplistic terms a repository is a collection of files and associated metadata) can be completely duplicated across multiple locations.
No doubt you have previously been working on a file (could be a document, spreadsheet, script or any other type of file) and got to a point where you have thought that you are starting to make edits that substantially change the file and therefore have considered saving the new file with a new name that indicates that it is a new version.

In the above diagram, new content is indicated in red and modifications in blue.
Whist this approach is ok, it is fairly limited and unsophisticated approach to versioning (keeping multiple versions of a file). Firstly, if you edit this file over many sessions and each time save with a different name, it becomes very difficult to either keep tract of what changes are associated with each version of the file, or the order in which the changes were made. This is massively compounded if a project comprises multiple files or has multiple authors.
Instead, imagine a system in which you could take a snapshot of state of your files and also provide a description outlining what changes you have made. Now imagine that the system was able to store and keep track of a succession of such versions in such a way that allows you to roll back to any previous versions of the files and exchange the entire history of changes with others collaborators - that is the purpose of git.
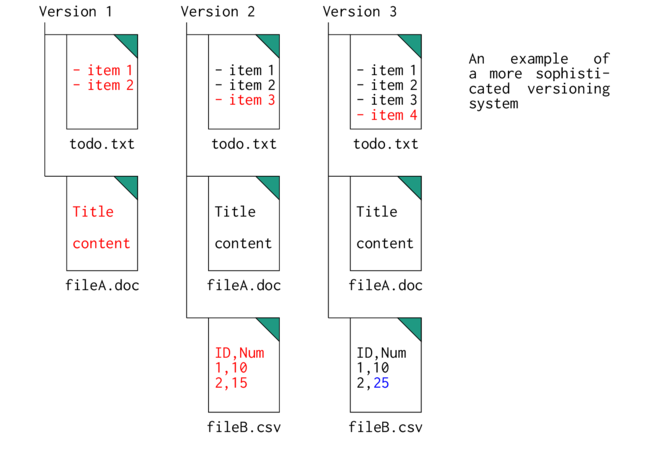
In the above diagram (which I must point out is not actually how git works), you can see that we are keeping track of multiple documents and potentially multiple changes within each document. What constitutes a version (as in how many changes and to what files) is completely arbitrary. Each individual edit can define a separate version.
One of the issues with the above system is that there is a lot of redundancy. With each new version an addition copy of the project's entire filesystem (all its files) must be stored. In the above case, Version 2 and 3 both contain identical copies of fileA.doc. Is there a way of reducing the required size of the snapshots by only keeping copies of those that have actually changed? this is what git achieves. Git versions (or snapshots known as commits) store files that have changed since the previous and files that have not changed are only represented by links to instances of these files within previous snapshots.
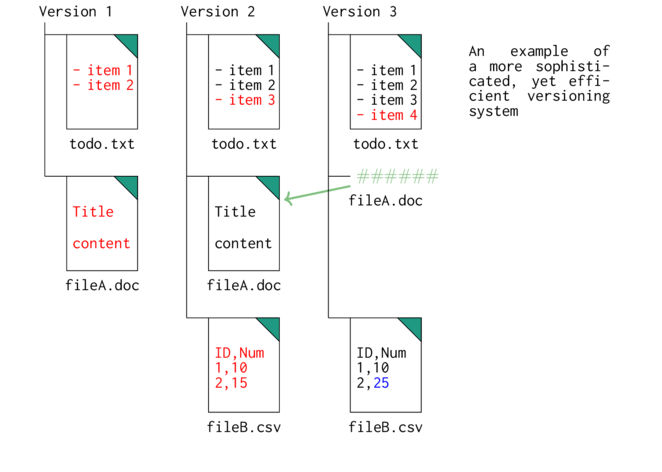
Now consider the following:
- You might have noticed that a new version can comprise multiple changes across multiple files. However, what if we have made numerous changes to numerous files over the course of an editing session (perhaps simultaneously addressing multiple different editing suggestions at a time), yet we did not want to lump all of these changes together into a single save point (snapshot). For example, the multiple changes might constitute addressing three independent issues, so although all edits were made simultaneously, we wish to record and describe the changes in three separate snapshots.
- What if this project had multiple contributors some of whom are working on new components of the project and some whom are working simultaneously on the same set of files? How can the system ensure that all contributors are in sync with each other and that new components are only introduced to the project proper once they are stable and agreed upon?
- What if there are files present within our project that we do not wish to keep track of. These files could be log files, compilation intermediates etc.
- Given that projects can comprise many files (some of which can be large), is it possible to store compressed files so as to reduce the storage and bandwidth burden?
Overview of git
The above discussion provides context for understanding how git works. Within git, files can exist in one of four states:
- untracked - these are files within the directory tree that are not to be included in the repository (not part of any snapshot)
- modified - these are files that have changed since the last snapshot
- staged - these are files that are nominated to be part of the next snapshot
- committed - these are files that are represented in a stored snapshot (called a commit). One a snapshot is committed, it is a permanent part of the repositories history
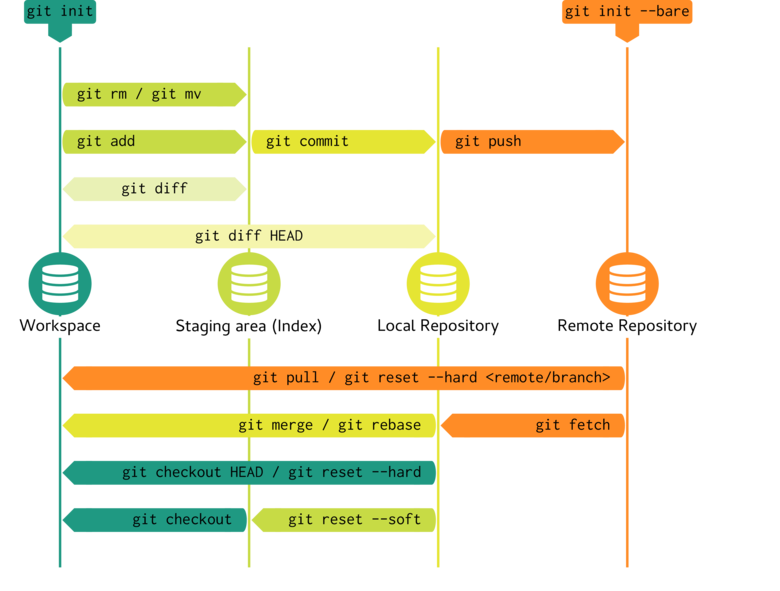
Conceptually, there are three main sections of a repository:
- Working directory - (or Workspace) is the obvious tree (set of files and folders) that is present on disc and comprises the actual files that you directly create, edit etc.
- Staging area - (or index) is a hidden file that contains metadata about the files to be included in the next snapshot (commit)
- Repository - the snapshots (commits). The commits are themselves just additional metadata pointing to a particular snapshot.
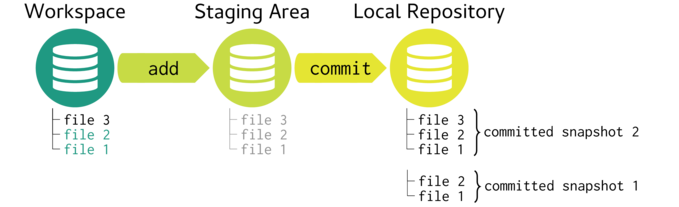
A superficial representation of some aspects of the git version control system follows. Here, the physical file tree in the workspace can be added to the staging area before this snapshot can be committed to the local repository.
After we add the two files (file 1 and file 2), both files will be considered in an
untracked state. Adding the files to the staging area changes their state to staged. Finally
when we commit, the files are in a committed state.

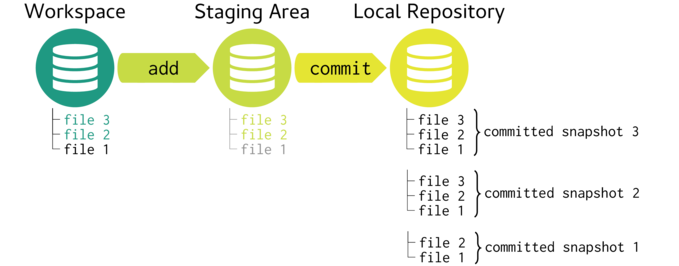
Now if we add another file (file 3) to our workspace, add this file to the staging area and then commit the change, the resulting committed snapshot in the local repository will resemble the workspace. Note, although the staging area contains all three files, only file 3 points to any new internal content - since file 1 and file 2 have unmodified, their instances in the staging area point to the same instances as previous. Similarly, the second commit in the Local repository will point to one new representation (associated with file 3) and two previous representations (associated with file 1 and file 2).
At this point, if we make a change to file 1, this file will be in a modified state until it is added to the staging area. After committing, the current committed snapshot (snapshot 3) is in sync with the workspace.
Initially, it might seem that there is an awful lot of duplication going on. For example, if we make a minor alteration to a file, why not just commit the change (delta) instead of an entirely new copy? Well, periodically, git will perform garbage collection on the repository. This process repacks the objects together into a single object that comprises only the original blobs and their subsequent deltas - thereby gaining efficiency. The process of garbage collection can also be forced at any time via:
git gc
During the evolution of most projects, situations arise in which we wish to start work on new components or features that might represent a substantial deviation from the main line of evolution. Often, we would very much like to be able to quarantine the main thread of the project from these new developments. For example, we may wish to be able to continue tweaking the main project files (in order to address minor issues and bugs), while at the same time, performing major edits that take the project in a different direction.
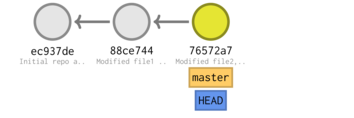
This is called branching. The main evolutionary thread of the project is referred to as the master branch. Deviations from the master branch are generally called branches and can be given any name (other than 'master' or 'HEAD'). For example, we could start a new branch called 'Feature' where we can evolve the project in one direction whilst still being able to actively develop the master branch at the same time. 'Feature' and 'master' branches are depicted in the left hand sequence of circles of the schematic below.
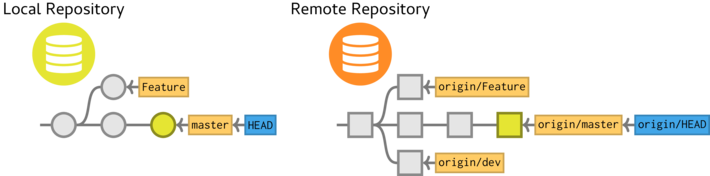
The circles represent commits (stored snapshots). We can see that the first commit is the common ancestor of the 'Feature' and 'master' branch. HEAD is a special reference that points to the tip of the currently active commit. It indicates where the next commit will be built onto. In diagram above, HEAD is pointing to the last commit in master. Hence the next commit will build on this commit. To develop the Feature branch further, we first have to move HEAD to the tip of the Feature branch.
We can later merge the Feature branch into the master branch in order to make the new changes mainstream.
To support collaboration, there can also be a remote repository (referred to as origin and depicted by the squares in the figure above). Unlike a local repository, a remote repository does not contain a workspace as files are not directly edited in the remote repository. Instead, the remote repository acts as a permanently available conduit between multiple contributors.
In the diagram above, we can see that the remote repository (origin) has an additional branch (in this called dev). The collaborator whose local repository is depicted above has either not yet obtained (pulled) this branch or has elected not to (as perhaps it is not a direction that they are involved in).
We also see that the master branch on the remote repository has a newer (additional) commit than the local repository.
Prior to working on branch a collaborator should first get any updates to the remote repository. This is a two step process. Firstly, the collaborator fetches any changes and then secondly merges those changes into their version of the branch. Collectively, these two actions are called a pull.
To make local changes available to others, the collaborator can push commits up to the remote repository. The pushed changes are applied directly to the nominated branch so it is the users responsibility to ensure as much as possible, their local repository already included the most recent remote repository changes (by always pulling before pushing).
Getting started
For the purpose of this tutorial, I will create a temporary folder the tmp folder of my home directory into which to create and manipulate repositories. To follow along with this tutorial, you are encouraged to do similarly.
mkdir ~/tmp/Repo1
Before using git, it is a good idea to define some global (applied to all your gits) settings. These include your name and email address and whilst not essential, they are applied to all actions you perform so the it is easier for others to track the route of changes etc.
git config --global user.email "your_email@whatever.com"
Setting up (initializing) a new repository
Initialize local repository

To create (or initialize) a new local repository, issue the git init command in the root of the working directory you wish to contain the git repository. This can be either an empty directory or contain an existing directory/file structure. The git init command will add a folder called .git to the directory. This is a one time operation.
cd ~/tmp/Repo1 git init
Initialized empty Git repository in /home/murray/tmp/Repo1/.git/
The .git folder contains all the necessary metadata to manage the repository.
ls -al
total 12 drwxr-xr-x 3 murray murray 4096 Jul 27 15:22 . drwxr-xr-x 44 murray murray 4096 Jul 27 15:22 .. drwxr-xr-x 7 murray murray 4096 Jul 27 15:22 .git
tree -a --charset unicode
.
`-- .git
|-- branches
|-- config
|-- description
|-- HEAD
|-- hooks
| |-- applypatch-msg.sample
| |-- commit-msg.sample
| |-- post-update.sample
| |-- pre-applypatch.sample
| |-- pre-commit.sample
| |-- prepare-commit-msg.sample
| |-- pre-push.sample
| |-- pre-rebase.sample
| |-- pre-receive.sample
| `-- update.sample
|-- info
| `-- exclude
|-- objects
| |-- info
| `-- pack
`-- refs
|-- heads
`-- tags
10 directories, 14 files
description:lists the name (and version) of a repository
HEAD:lists a reference to the current checked out commit.
hooks:a directory containing scripts that are executed at various stages (e.g. pre-push.sample is an example of a script executed prior to pushing)
info:contains a file exclude that lists exclusions (files not to be tracked). This is like .gitignore, except is not versioned.
objects:this directory contains SHA indexed files being tracked
refs:a master copy of all the repository refs
logs:contains a history of each branch
Note, at this stage, no files are being tracked, that is, they are not part of the repository.
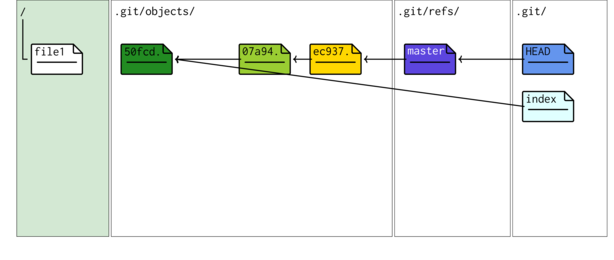
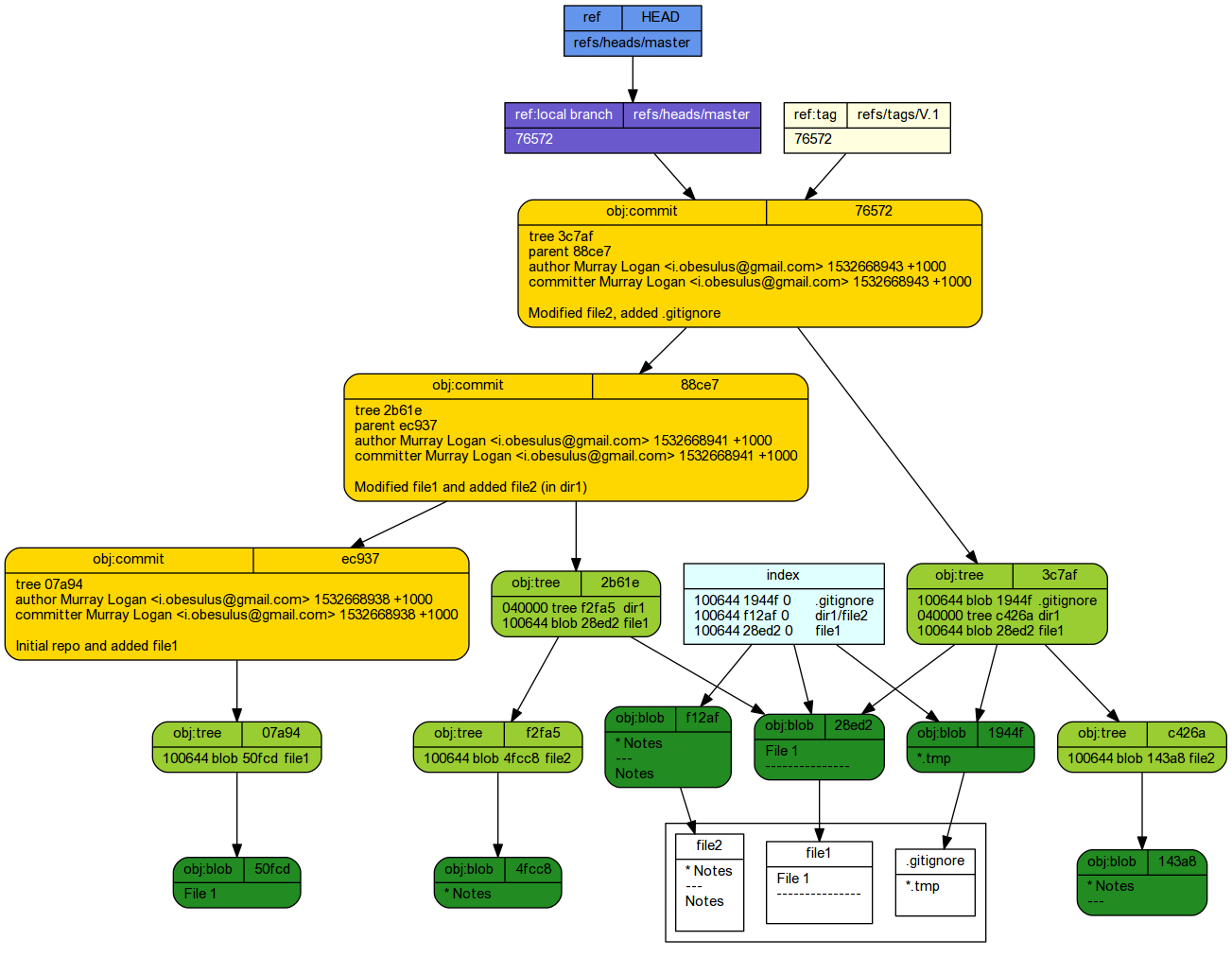
To assist in gaining a greater understanding of the workings of git, we will use a series of schematics diagrams representing the contents of four important sections of the repository. In the figure below, the left hand panel represents the contents of the root directory (excluding the .git folder) - this is the workspace and is currently empty.
The three white panels represent three important parts of the inner structure of the .git folder. A newly initialized repository is relatively devoid of any specific metadata since there are no staged or committed files. In the root of the .git folder, there is a file called HEAD.
The figure is currently very sparse. However, as the repository grows, so the figure will become more complex.


Initializing a shared (remote) repository

The master repository for sharing should not contain the working directory as such - only the .git tree and the .gitignore file. Typically the point of a remote repository is to act as a perminantly available repository from which multiple uses can exchange files. Consequently, those accessing this repository should only be able to interact with the .git metadata - they do not directly modify any files.
Since a remote repository is devode of the working files and directories, it is referred to as bare To create a bare remote repository, issue the git init --bare command after loggin in to the remote location.
Cloning an existing repository

To get your own local copy of an existing repository, issue the git clone <repo url> command in the root of the working directory you wish to contain the git repository. The repo url points to the location of the existing repository to be cloned. This is also a one time operation and should be issued in an otherwise empty directory.
The repo url can be located on any accessible filesytem (local or remote). The cloning process also stores a link back to the original location of the repository (called origin). This provides a convenient way for the system to keep track of where the local repository should exchange files.
Many git repositories are hosted on sites such as github, gitlab or bitbucket. Within an online git repository, these sites provide url links for cloning.
By default a new directory will be generated with the name of the repository. You can provide an alternative name:
Tracking files
The basic workflow for tracking files is a two step process in which one or more files are first added to the staging area before they are committed to the local repository. The staging area acts as a little like a snapshot of what the repository will look like once the changes have been committed. The staging area also acts like a buffer between the files in the workspace (actual local copy of files) and the local repository (committed changes).
The reason that this is a two step process is that it allows the user to make edits to numerous files, yet block the commits in smaller chunks to help isolate changes in case there is a need to roll back to previous versions.
Staging files
When a file is first added to the staging area, a full copy of that file is added to the staging area (not just the file diffs as in other versioning systems).
To demonstrate lets create a file (a simple text file containing the string saying 'File 1') and add it to the staging area.
echo 'File 1' > file1
Now lets add this file to the staging area
git add file1
To see the status of the repository (that is, what files are being tracked), we issue the git status command
git status
On branch master Initial commit Changes to be committed: (use "git rm --cached <file>..." to unstage) new file: file1
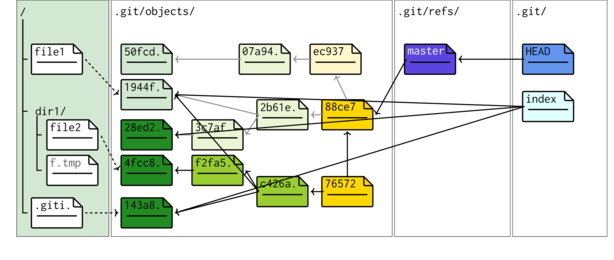
Our simple overview schematic represents the staging of file 1.

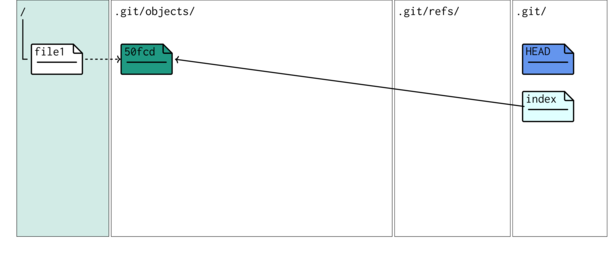
A schematic of the internal working of git shows in .git/objects a blob has been created. This is a compressed version of file1. Its filename is a 40 digit SHA-1 checksum has representing the contents of the file1. To re-iterate, the blob name is a SHA-1 hash of the file contents (actually, the first two digits form a folder and the remaining 38 form the filename).
We can look at the contents of this blob using the git cat-file command. This command outputs the contents of a compressed object (blob, tree, commit) from either the objects name (or unique fraction thereof) or its tag (we will discuss tags later).
git cat-file blob 50fcd
File 1
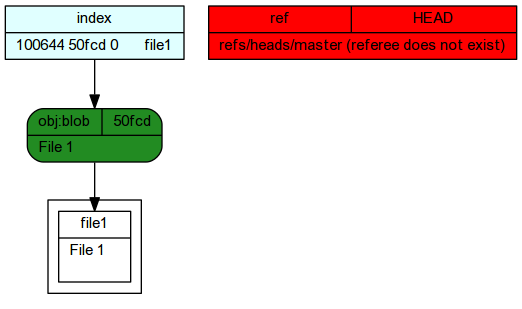
The add process also created a index file. This file simply points to the blob that is part of the snapshot. The git internals schematic illustrates the internal changes in response to staging a file.
Commit to local repository

To commit a set of changes from the staging area to the local repository, we issue the git commit command. We usually add the -m switch to explicitly supply a message to be associated with the commit. This message should ideally describe what the changes the commit introduces to the repository.
git commit -m 'Initial repo and added file1'
[master (root-commit) ec937de] Initial repo and added file1 1 file changed, 1 insertion(+) create mode 100644 file1
We now see that the status has changed. It indicates that the tree in the workspace is in sync with the repository.
git status
On branch master +\n othing to commit, working tree clean
Our simple overview schematic represents the staging of file 1.

The following modifications have occurred (in reverse order to how they actually occur):
- The master branch reference was created. There is currently only a single branch (more on branches later).
The branch reference point to (indicates) which commit is the current commit within a branch.
cat .git/refs/heads/master
ec937de317d7f533a6d9d4c261b4788ead8a167e
- A commit was created. This points to a tree (which itself points to the blob representing file1) as
well as other important metadata (such as who made the commit and when). Since the time stamp will be unique each time a snapshot
is commited, so too the name of the commit (as a SHA-1 checksum hash) will differ. To reiterate, the names of blobs and trees are
determined by contents alone, commit names are also incorporate commit timestamp and details of the committer - and are thus virtually unique.
git cat-file commit ec937
tree 07a941b332d756f9a8acc9fdaf58aab5c7a43f64 author Murray Logan <i.obesulus@gmail.com> 1532668938 +1000 committer Murray Logan <i.obesulus@gmail.com> 1532668938 +1000 Initial repo and added file1
-
A tree object was created. This represents the directory tree of the snapshot and thus points to the blobs.
git ls-tree 07a94
100644 blob 50fcd26d6ce3000f9d5f12904e80eccdc5685dd1 file1
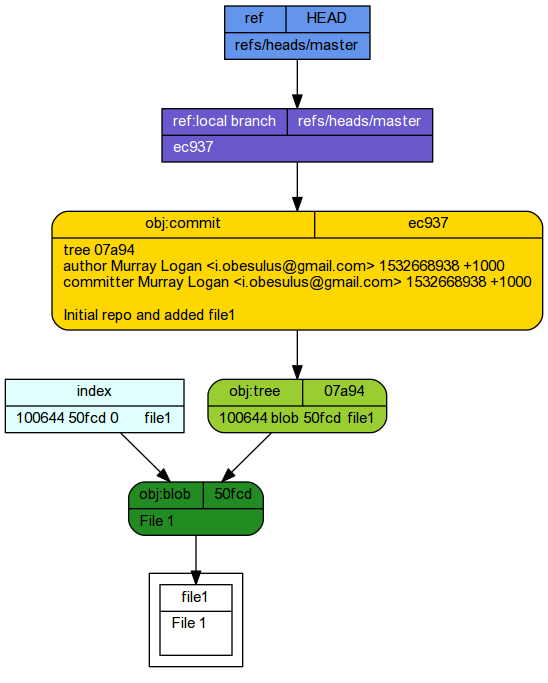
Committing staged changes creates an object under the .git tree.
tree -a --charset unicode
.
|-- file1
`-- .git
|-- branches
|-- COMMIT_EDITMSG
|-- config
|-- description
|-- HEAD
|-- hooks
| |-- applypatch-msg.sample
| |-- commit-msg.sample
| |-- post-update.sample
| |-- pre-applypatch.sample
| |-- pre-commit.sample
| |-- prepare-commit-msg.sample
| |-- pre-push.sample
| |-- pre-rebase.sample
| |-- pre-receive.sample
| `-- update.sample
|-- index
|-- info
| `-- exclude
|-- logs
| |-- HEAD
| `-- refs
| `-- heads
| `-- master
|-- objects
| |-- 07
| | `-- a941b332d756f9a8acc9fdaf58aab5c7a43f64
| |-- 50
| | `-- fcd26d6ce3000f9d5f12904e80eccdc5685dd1
| |-- ec
| | `-- 937de317d7f533a6d9d4c261b4788ead8a167e
| |-- info
| `-- pack
`-- refs
|-- heads
| `-- master
`-- tags
16 directories, 23 files
git cat-file -p HEAD
tree 07a941b332d756f9a8acc9fdaf58aab5c7a43f64 author Murray Logan <i.obesulus@gmail.com> 1532668938 +1000 committer Murray Logan <i.obesulus@gmail.com> 1532668938 +1000 Initial repo and added file1
git cat-file -p HEAD^{tree}
100644 blob 50fcd26d6ce3000f9d5f12904e80eccdc5685dd1 file1
git log --oneline
ec937de Initial repo and added file1
More changes

Whenever a file is added or modified, if the changes are to be tracked, the file needs to be added to the staging area. Lets demonstrate by modifying file1 and adding an additional file (this time to a subfolder).
echo '---------------' >> file1 mkdir dir1 echo '* Notes' > dir1/file2 git add file1 dir1/file2
git status
On branch master Changes to be committed: (use "git reset HEAD <file>..." to unstage) new file: dir1/file2 modified: file1
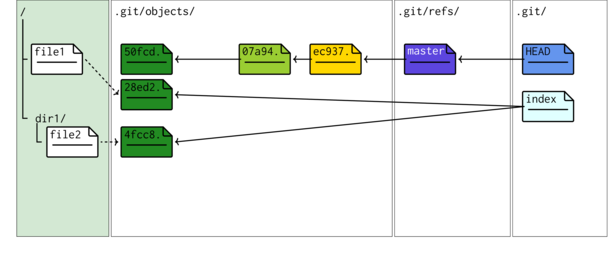
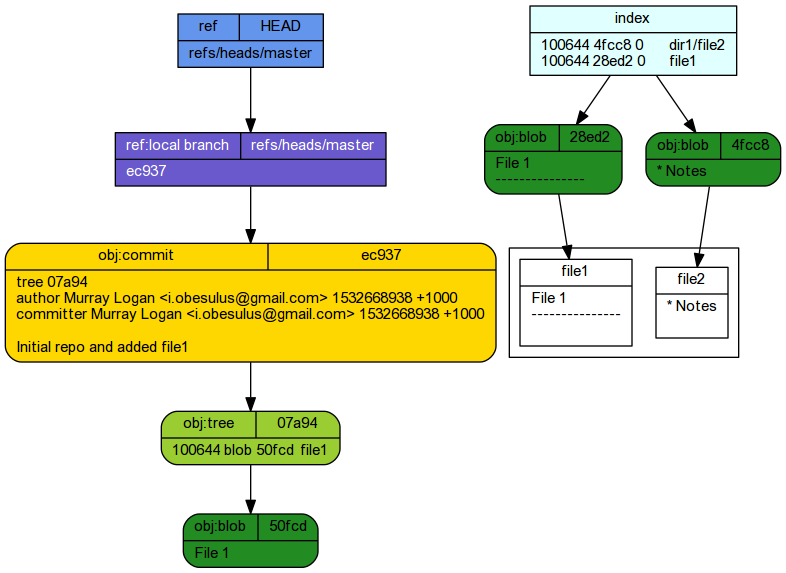
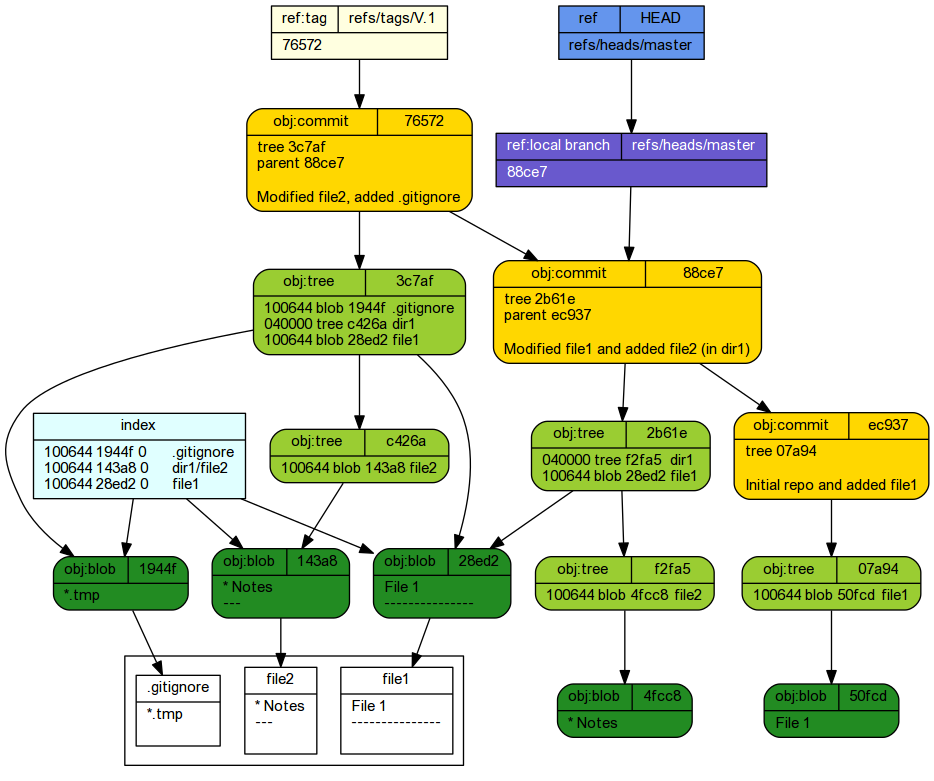
Staging file1 and file2 has:
- updated the index file.
git ls-files --stage
100644 4fcc8f85f738deb6cbb17db1ed3da241ad6cdf39 0 dir1/file2 100644 28ed2456cbfa8a18a280c8af5b422e91e88ff64d 0 file1
- Two new blobs have been generated. One representing the modified file1 and the other representing file2 in the dir1 folder. The blob that represented the original file1 contents is still present and indeed is still the one currently committed. Blobs are not erased or modified.
Now if we commit this snapshot,
git commit -m 'Modified file1 and added file2 (in dir1)'
[master 88ce744] Modified file1 and added file2 (in dir1) 2 files changed, 2 insertions(+) create mode 100644 dir1/file2
-
The master branch now points to the new commit.
cat .git/refs/heads/master
88ce744613244cfeb24475f4a0375106527809d1
git reflog
88ce744 HEAD@{0}: commit: Modified file1 and added file2 (in dir1) ec937de HEAD@{1}: commit (initial): Initial repo and added file1 - A new commit was created. This points to a new root tree object and also points to the previous commit (its parent).
git cat-file commit 88ce7
tree 2b61e2b3db9d1708269cf9d1aeaae2b0a2af1a23 parent ec937de317d7f533a6d9d4c261b4788ead8a167e author Murray Logan <i.obesulus@gmail.com> 1532668941 +1000 committer Murray Logan <i.obesulus@gmail.com> 1532668941 +1000 Modified file1 and added file2 (in dir1)
-
A new root tree was created. This points to a blob representing the modified file1 as well as a newly created
sub-directory tree representing the dir1 folder.
git ls-tree 2b61e
040000 tree f2fa54609fe5e918f365e0d5ffaf9a3aea88d541 dir1 100644 blob 28ed2456cbfa8a18a280c8af5b422e91e88ff64d file1
git cat-file -p HEAD^{tree}040000 tree f2fa54609fe5e918f365e0d5ffaf9a3aea88d541 dir1 100644 blob 28ed2456cbfa8a18a280c8af5b422e91e88ff64d file1
-
A new sub-directory root tree was created. This points to a blob representing the modified file1 as well as a newly created
subtree tree representing the file2 file within the dir1 folder.
git ls-tree f2fa5
100644 blob 4fcc8f85f738deb6cbb17db1ed3da241ad6cdf39 file2
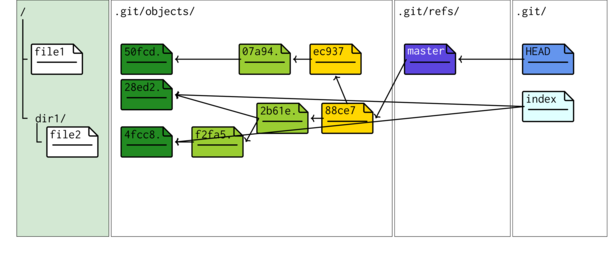
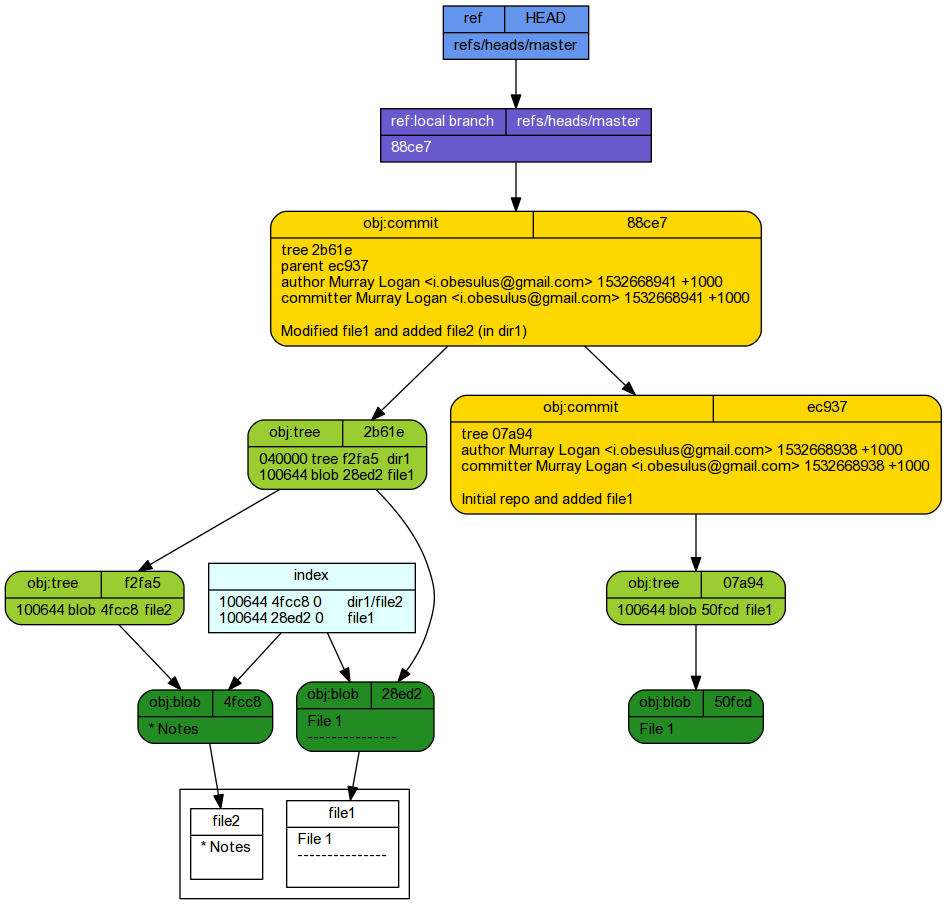
Committing staged changes creates an object under the .git tree.
tree -a --charset unicode
.
|-- dir1
| `-- file2
|-- file1
`-- .git
|-- branches
|-- COMMIT_EDITMSG
|-- config
|-- description
|-- HEAD
|-- hooks
| |-- applypatch-msg.sample
| |-- commit-msg.sample
| |-- post-update.sample
| |-- pre-applypatch.sample
| |-- pre-commit.sample
| |-- prepare-commit-msg.sample
| |-- pre-push.sample
| |-- pre-rebase.sample
| |-- pre-receive.sample
| `-- update.sample
|-- index
|-- info
| `-- exclude
|-- logs
| |-- HEAD
| `-- refs
| `-- heads
| `-- master
|-- objects
| |-- 07
| | `-- a941b332d756f9a8acc9fdaf58aab5c7a43f64
| |-- 28
| | `-- ed2456cbfa8a18a280c8af5b422e91e88ff64d
| |-- 2b
| | `-- 61e2b3db9d1708269cf9d1aeaae2b0a2af1a23
| |-- 4f
| | `-- cc8f85f738deb6cbb17db1ed3da241ad6cdf39
| |-- 50
| | `-- fcd26d6ce3000f9d5f12904e80eccdc5685dd1
| |-- 88
| | `-- ce744613244cfeb24475f4a0375106527809d1
| |-- ec
| | `-- 937de317d7f533a6d9d4c261b4788ead8a167e
| |-- f2
| | `-- fa54609fe5e918f365e0d5ffaf9a3aea88d541
| |-- info
| `-- pack
`-- refs
|-- heads
| `-- master
`-- tags
22 directories, 29 files
git cat-file -p HEAD
tree 2b61e2b3db9d1708269cf9d1aeaae2b0a2af1a23 parent ec937de317d7f533a6d9d4c261b4788ead8a167e author Murray Logan <i.obesulus@gmail.com> 1532668941 +1000 committer Murray Logan <i.obesulus@gmail.com> 1532668941 +1000 Modified file1 and added file2 (in dir1)
git cat-file -p HEAD^{tree}
040000 tree f2fa54609fe5e918f365e0d5ffaf9a3aea88d541 dir1 100644 blob 28ed2456cbfa8a18a280c8af5b422e91e88ff64d file1
Now you might be wondering... What if I have modified many files and I want to stage them all. Do I really have to add each file individually? Is there not some way to add multiple files at a time? The answer of course is yes. To stage all files (including those in subdirectories) we issue the git add . command (notice the dot).
git add .
.gitignore
Whilst it is convenient to not have to list every file that you want to be staged (added), what about files that we don't want to get staged and committed. It is also possible to define a file (called .gitignore) that is a list of files (or file patterns) that are to be excluded when we request all files be added. This functionality is provided via the .gitignore file that must be in the root of the repository working directory.
For example, we may have temporary files or automatic backup files or files generated as intermediates in a compile process etc that get generated. These files are commonly generated in the process of working with files in a project, yet we do not necessarily wish for them to be tracked. Often these files have very predictable filename pattern (such as ending with a # or ~ symbol or having a specific file extension such as .aux. Hence, we can create a.gitignore to exclude these. Lets start by modifying the file2 and creating a new file f.tmp (that we want to ignore).
echo '---' >> dir1/file2 echo 'temp' > dir1/f.tmp
echo '*.tmp' > .gitignore cat .gitignore
*.tmp
| Entry | Meaning | |
|---|---|---|
| file1 | DO NOT stage (add) file1 | |
| *.tmp | DO NOT stage (add) any file ending in .tmp | |
| /dir1/* | DO NOT stage (add) the folder called dir1 (or any of its contents) unless this is specifically negated (see next line) | |
| !/dir1/file2 | DO stage (add) the file called file2 that is within the dir1 folder |
Now when we go to add all files to the staging area, those that fall under the exclude rules will be ignored
git add .
git status
On branch master Changes to be committed: (use "git reset HEAD <file>..." to unstage) new file: .gitignore modified: dir1/file2
git commit -m 'Modified file2, added .gitignore'
[master 76572a7] Modified file2, added .gitignore 2 files changed, 2 insertions(+) create mode 100644 .gitignore
git status
On branch master +\n othing to commit, working tree clean
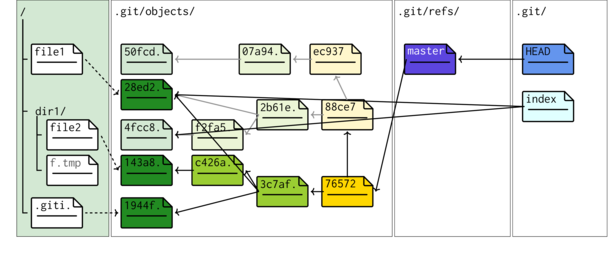
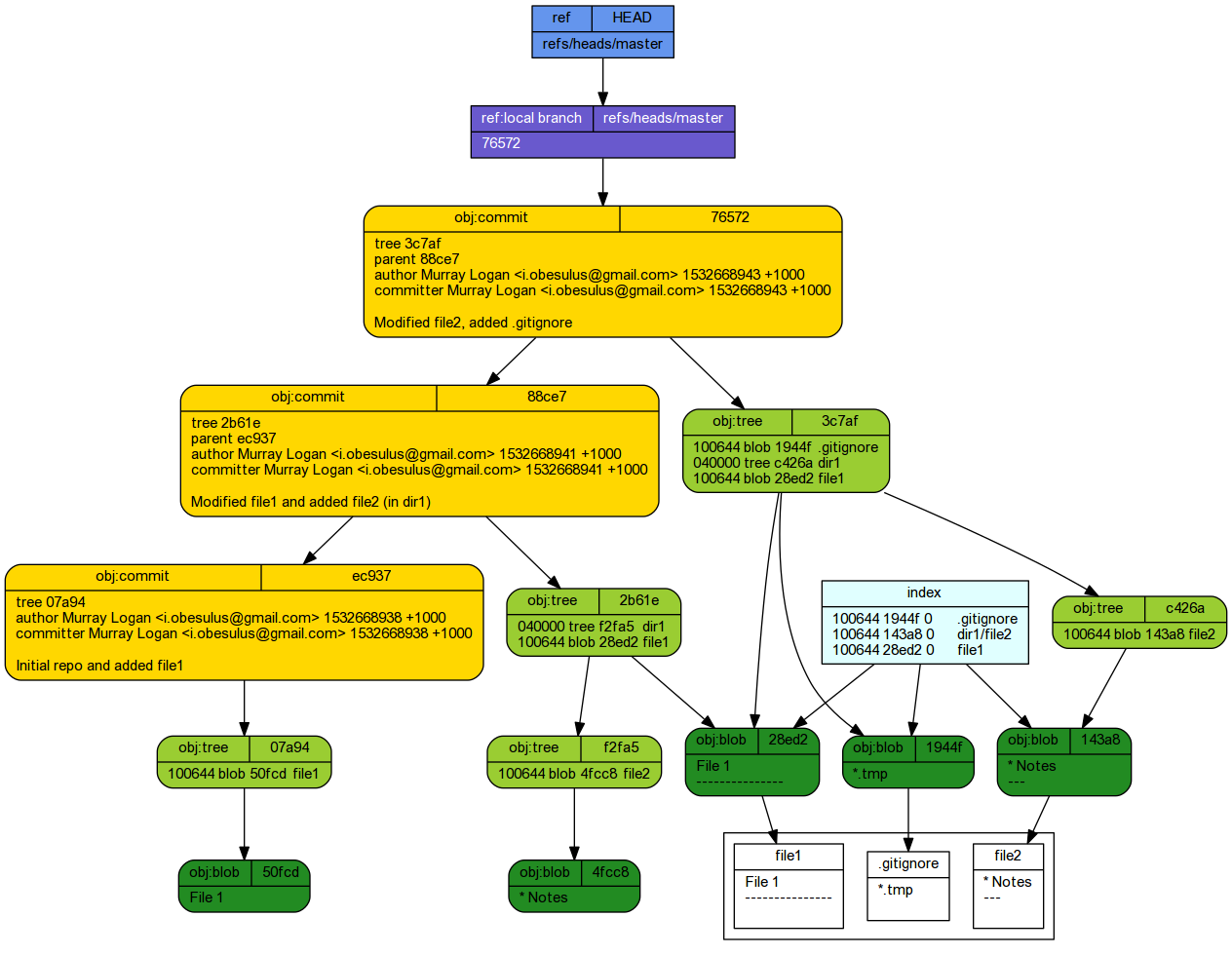
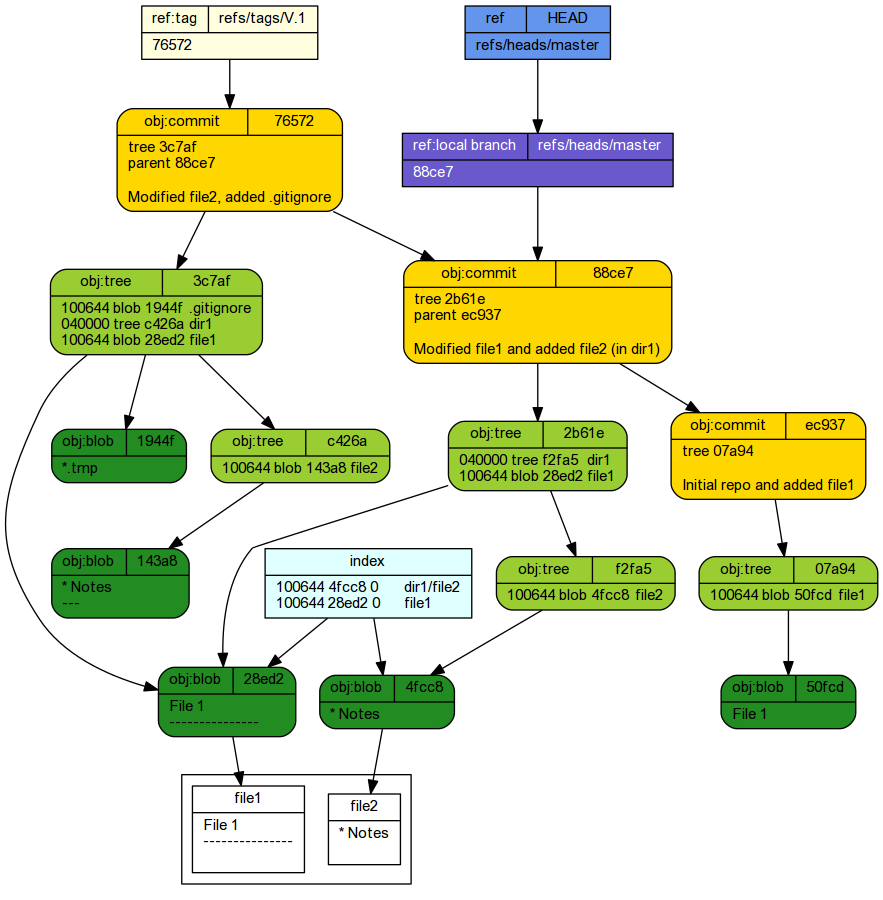
Committing staged changes creates an object under the .git tree.
tree -a --charset unicode
. |-- dir1 | |-- file2 | `-- f.tmp |-- file1 |-- .git | |-- branches | |-- COMMIT_EDITMSG | |-- config | |-- description | |-- HEAD | |-- hooks | | |-- applypatch-msg.sample | | |-- commit-msg.sample | | |-- post-update.sample | | |-- pre-applypatch.sample | | |-- pre-commit.sample | | |-- prepare-commit-msg.sample | | |-- pre-push.sample | | |-- pre-rebase.sample | | |-- pre-receive.sample | | `-- update.sample | |-- index | |-- info | | `-- exclude | |-- logs | | |-- HEAD | | `-- refs | | `-- heads | | `-- master | |-- objects | | |-- 07 | | | `-- a941b332d756f9a8acc9fdaf58aab5c7a43f64 | | |-- 14 | | | `-- 3a8bb5a2cc05a91f83a87af18c8eb5885a375c | | |-- 19 | | | `-- 44fd61e7c53bcc19e6f3eb94cc800508944a25 | | |-- 28 | | | `-- ed2456cbfa8a18a280c8af5b422e91e88ff64d | | |-- 2b | | | `-- 61e2b3db9d1708269cf9d1aeaae2b0a2af1a23 | | |-- 3c | | | `-- 7af0d3ccea71c9af82fa0ce68532272edcf1b8 | | |-- 4f | | | `-- cc8f85f738deb6cbb17db1ed3da241ad6cdf39 | | |-- 50 | | | `-- fcd26d6ce3000f9d5f12904e80eccdc5685dd1 | | |-- 76 | | | `-- 572a7b7b4f01f4f18d7c66d0ca3279aeeec197 | | |-- 88 | | | `-- ce744613244cfeb24475f4a0375106527809d1 | | |-- c4 | | | `-- 26a67af50d13828ec73b3c560b2648e2f3dc08 | | |-- ec | | | `-- 937de317d7f533a6d9d4c261b4788ead8a167e | | |-- f2 | | | `-- fa54609fe5e918f365e0d5ffaf9a3aea88d541 | | |-- info | | `-- pack | `-- refs | |-- heads | | `-- master | `-- tags `-- .gitignore 27 directories, 36 files
git cat-file -p HEAD
tree 3c7af0d3ccea71c9af82fa0ce68532272edcf1b8 parent 88ce744613244cfeb24475f4a0375106527809d1 author Murray Logan <i.obesulus@gmail.com> 1532668943 +1000 committer Murray Logan <i.obesulus@gmail.com> 1532668943 +1000 Modified file2, added .gitignore
git cat-file -p HEAD^{tree}
100644 blob 1944fd61e7c53bcc19e6f3eb94cc800508944a25 .gitignore 040000 tree c426a67af50d13828ec73b3c560b2648e2f3dc08 dir1 100644 blob 28ed2456cbfa8a18a280c8af5b422e91e88ff64d file1
Inspecting a repository
For this section, will will be working on the repository built up in the previous section.
tree -ra -L 2 --charset ascii
.
|-- .gitignore
|-- .git
| |-- refs
| |-- objects
| |-- logs
| |-- info
| |-- index
| |-- hooks
| |-- HEAD
| |-- description
| |-- config
| |-- COMMIT_EDITMSG
| `-- branches
|-- file1
`-- dir1
|-- f.tmp
`-- file2
8 directories, 9 files
mkdir ~/tmp/Repo1 cd ~/tmp/Repo1 git init echo 'File 1' > file1 git add file1 git commit -m 'Initial repo and added file1' echo '---------------' >> file1 mkdir dir1 echo '* Notes' > dir1/file2 git add file1 dir1/file2 git commit -m 'Modified file1 and added file2 (in dir1)' echo '---' > dir1/file2 echo 'temp' > dir1/f.tmp echo '*.tmp' > .gitignore git add . git commit -m 'Modified file2, added .gitignore'
Status of workspace and staging area
Recall that within the .git environment, files can be in one of four states:
- untracked
- modified
- staged
- committed
git status
On branch master +\n othing to commit, working tree clean
log of commits
The git log command allows us to review the history of committed snapshots
git log
commit 76572a7b7b4f01f4f18d7c66d0ca3279aeeec197
Author: Murray Logan <i.obesulus@gmail.com>
Date: Fri Jul 27 15:22:23 2018 +1000
Modified file2, added .gitignore
commit 88ce744613244cfeb24475f4a0375106527809d1
Author: Murray Logan <i.obesulus@gmail.com>
Date: Fri Jul 27 15:22:21 2018 +1000
Modified file1 and added file2 (in dir1)
commit ec937de317d7f533a6d9d4c261b4788ead8a167e
Author: Murray Logan <i.obesulus@gmail.com>
Date: Fri Jul 27 15:22:18 2018 +1000
Initial repo and added file1
We can see that in my case some fool called 'Murray Logan' has made a total of three commits. We can also see the date/time that the commits were made as well as the supplied commit comment.
Over time repositories accumulate a large number of commits, to only review the last 2 commits, we could issue the git log -n 2 command.
git log -n 2
commit 76572a7b7b4f01f4f18d7c66d0ca3279aeeec197
Author: Murray Logan <i.obesulus@gmail.com>
Date: Fri Jul 27 15:22:23 2018 +1000
Modified file2, added .gitignore
commit 88ce744613244cfeb24475f4a0375106527809d1
Author: Murray Logan <i.obesulus@gmail.com>
Date: Fri Jul 27 15:22:21 2018 +1000
Modified file1 and added file2 (in dir1)
| Option | Example |
|---|---|
| --oneline Condensed view |
git log --oneline 76572a7 Modified file2, added .gitignore 88ce744 Modified file1 and added file2 (in dir1) ec937de Initial repo and added file1 |
| --stat Indicates number of changes |
git log --stat commit 76572a7b7b4f01f4f18d7c66d0ca3279aeeec197
Author: Murray Logan <i.obesulus@gmail.com>
Date: Fri Jul 27 15:22:23 2018 +1000
Modified file2, added .gitignore
.gitignore | 1 +
dir1/file2 | 1 +
2 files changed, 2 insertions(+)
commit 88ce744613244cfeb24475f4a0375106527809d1
Author: Murray Logan <i.obesulus@gmail.com>
Date: Fri Jul 27 15:22:21 2018 +1000
Modified file1 and added file2 (in dir1)
dir1/file2 | 1 +
file1 | 1 +
2 files changed, 2 insertions(+)
commit ec937de317d7f533a6d9d4c261b4788ead8a167e
Author: Murray Logan <i.obesulus@gmail.com>
Date: Fri Jul 27 15:22:18 2018 +1000
Initial repo and added file1
file1 | 1 +
1 file changed, 1 insertion(+)
|
| -p Displays the full diff of each commit |
git log -p commit 76572a7b7b4f01f4f18d7c66d0ca3279aeeec197
Author: Murray Logan <i.obesulus@gmail.com>
Date: Fri Jul 27 15:22:23 2018 +1000
Modified file2, added .gitignore
diff --git a/.gitignore b/.gitignore
+\n ew file mode 100644
index 0000000..1944fd6
--- /dev/null
+\n ++ b/.gitignore
@@ -0,0 +1 @@
+\n *.tmp
diff --git a/dir1/file2 b/dir1/file2
index 4fcc8f8..143a8bb 100644
--- a/dir1/file2
+\n ++ b/dir1/file2
@@ -1 +1,2 @@
* Notes
+\n ---
commit 88ce744613244cfeb24475f4a0375106527809d1
Author: Murray Logan <i.obesulus@gmail.com>
Date: Fri Jul 27 15:22:21 2018 +1000
Modified file1 and added file2 (in dir1)
diff --git a/dir1/file2 b/dir1/file2
+\n ew file mode 100644
index 0000000..4fcc8f8
--- /dev/null
+\n ++ b/dir1/file2
@@ -0,0 +1 @@
+\n * Notes
diff --git a/file1 b/file1
index 50fcd26..28ed245 100644
--- a/file1
+\n ++ b/file1
@@ -1 +1,2 @@
File 1
+\n ---------------
commit ec937de317d7f533a6d9d4c261b4788ead8a167e
Author: Murray Logan <i.obesulus@gmail.com>
Date: Fri Jul 27 15:22:18 2018 +1000
Initial repo and added file1
diff --git a/file1 b/file1
+\n ew file mode 100644
index 0000000..50fcd26
--- /dev/null
+\n ++ b/file1
@@ -0,0 +1 @@
+\n File 1
|
| --author="<name>" Filter by author |
git log --author="Murray" commit 76572a7b7b4f01f4f18d7c66d0ca3279aeeec197
Author: Murray Logan <i.obesulus@gmail.com>
Date: Fri Jul 27 15:22:23 2018 +1000
Modified file2, added .gitignore
commit 88ce744613244cfeb24475f4a0375106527809d1
Author: Murray Logan <i.obesulus@gmail.com>
Date: Fri Jul 27 15:22:21 2018 +1000
Modified file1 and added file2 (in dir1)
commit ec937de317d7f533a6d9d4c261b4788ead8a167e
Author: Murray Logan <i.obesulus@gmail.com>
Date: Fri Jul 27 15:22:18 2018 +1000
Initial repo and added file1
|
| --grep="<pattern>" Filter by regex pattern of commit message |
git log --grep="Modified" commit 76572a7b7b4f01f4f18d7c66d0ca3279aeeec197
Author: Murray Logan <i.obesulus@gmail.com>
Date: Fri Jul 27 15:22:23 2018 +1000
Modified file2, added .gitignore
commit 88ce744613244cfeb24475f4a0375106527809d1
Author: Murray Logan <i.obesulus@gmail.com>
Date: Fri Jul 27 15:22:21 2018 +1000
Modified file1 and added file2 (in dir1)
|
| <file> Filter by filename |
git log notes.org fatal: ambiguous argument 'notes.org': unknown revision or path not in the working tree. Use '--' to separate paths from revisions, like this: 'git <command> [<revision>...] -- [<file>...]' |
| <file> Filter by filename |
git log --graph --decorate --oneline * 76572a7 (HEAD -> master) Modified file2, added .gitignore * 88ce744 Modified file1 and added file2 (in dir1) * ec937de Initial repo and added file1 |
reflog
Another way to explore the commit history is to look at the reflog. This is a log of the branch references. This approach is more useful when we have multiple branches and so will be visited in the section on branching.
git reflog
76572a7 HEAD@{0}: commit: Modified file2, added .gitignore
88ce744 HEAD@{1}: commit: Modified file1 and added file2 (in dir1)
ec937de HEAD@{2}: commit (initial): Initial repo and added file1
diff
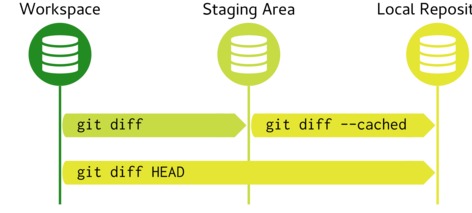
Two of the three commits in our repository involved modifications to a file. The git diff allows us to explore differences between:
- the workspace and the staging area (index)
The output indicates that we are comparing the blob representing dir1/file2 in the index (staging area) with the newly modified dir1/file2. The next couple of rows indicate that the indexed version will be represented by a '-' sign and the new version will be represented by a '+' sign. The next row (which is surrounded in a pair of @ signs, indicates that there are two lines that have changed. Finally the next two rows show that a charrage return has been added to the end of the first line and the new version has added the word 'Notes' to the next line.
# lets modify dir1/file2 echo 'Notes' >> dir1/file2 git diff
diff --git a/dir1/file2 b/dir1/file2 index 143a8bb..f12af0a 100644 --- a/dir1/file2 +\n ++ b/dir1/file2 @@ -1,2 +1,3 @@ * Notes --- +\n Notes
- the staging area and the last commit
Once we stage the modifications, we see that the same differences are recorded.
git add . git diff --cached
diff --git a/dir1/file2 b/dir1/file2 index 143a8bb..f12af0a 100644 --- a/dir1/file2 +\n ++ b/dir1/file2 @@ -1,2 +1,3 @@ * Notes --- +\n Notes
- the index and a tree (in this case, the current tree)
git diff --cached HEAD^{tree}diff --git a/dir1/file2 b/dir1/file2 index 143a8bb..f12af0a 100644 --- a/dir1/file2 +\n ++ b/dir1/file2 @@ -1,2 +1,3 @@ * Notes --- +\n Notes
- the workspace and the current commit
git diff HEAD
diff --git a/dir1/file2 b/dir1/file2 index 143a8bb..f12af0a 100644 --- a/dir1/file2 +\n ++ b/dir1/file2 @@ -1,2 +1,3 @@ * Notes --- +\n Notes
- two commits (e.g. previous and current commits)
git diff HEAD^ HEAD
diff --git a/.gitignore b/.gitignore +\n ew file mode 100644 index 0000000..1944fd6 --- /dev/null +\n ++ b/.gitignore @@ -0,0 +1 @@ +\n *.tmp diff --git a/dir1/file2 b/dir1/file2 index 4fcc8f8..143a8bb 100644 --- a/dir1/file2 +\n ++ b/dir1/file2 @@ -1 +1,2 @@ * Notes +\n ---
- two trees (first example, the current and previous commit trees)
git diff HEAD^{tree} HEAD^^{tree}diff --git a/.gitignore b/.gitignore deleted file mode 100644 index 1944fd6..0000000 --- a/.gitignore +\n ++ /dev/null @@ -1 +0,0 @@ -*.tmp diff --git a/dir1/file2 b/dir1/file2 index 143a8bb..4fcc8f8 100644 --- a/dir1/file2 +\n ++ b/dir1/file2 @@ -1,2 +1 @@ * Notes ----
git diff 61742 39183
fatal: ambiguous argument '61742': unknown revision or path not in the working tree. Use '--' to separate paths from revisions, like this: 'git <command> [<revision>...] -- [<file>...]'
- two blobs (indeed any two objects)
git diff 50fcd 28ed2
diff --git a/50fcd b/28ed2 index 50fcd26..28ed245 100644 --- a/50fcd +\n ++ b/28ed2 @@ -1 +1,2 @@ File 1 +\n ---------------
ls-files
We can list the files that comprise the repo by:
git ls-files
.gitignore dir1/file2 file1
Tags
Although it is possible to track the history of a repository via its commit sha1 names, most find it more convenient to apply tags to certain milestone commits. For example, a particular commit might represent a specific point in the history of a project - such as a release version. Git tags allow us to apply more human readable flags.
git tag V.1
git log --graph --decorate --oneline
* 76572a7 (HEAD -> master, tag: V.1) Modified file2, added .gitignore * 88ce744 Modified file1 and added file2 (in dir1) * ec937de Initial repo and added file1
git reflog
76572a7 HEAD@{0}: commit: Modified file2, added .gitignore
88ce744 HEAD@{1}: commit: Modified file1 and added file2 (in dir1)
ec937de HEAD@{2}: commit (initial): Initial repo and added file1
Branching
Again we will start with our repository For this section, will will be working on the repository built up in the previous section.
tree -ra -L 2 --charset ascii
.
|-- .gitignore
|-- .git
| |-- refs
| |-- objects
| |-- logs
| |-- info
| |-- index
| |-- hooks
| |-- HEAD
| |-- description
| |-- config
| |-- COMMIT_EDITMSG
| `-- branches
|-- file1
`-- dir1
|-- f.tmp
`-- file2
8 directories, 9 files
mkdir ~/tmp/Repo1 cd ~/tmp/Repo1 git init echo 'File 1' > file1 git add file1 git commit -m 'Initial repo and added file1' echo '---------------' >> file1 mkdir dir1 echo '* Notes' > dir1/file2 git add file1 dir1/file2 git commit -m 'Modified file1 and added file2 (in dir1)' echo '---' > dir1/file2 echo 'temp' > dir1/f.tmp echo '*.tmp' > .gitignore git add . git commit -m 'Modified file2, added .gitignore'
Lets assume that the current commit represents a largely stable project. We are about to embark on a substantial modification in the form of a new feature that will involve editing file1 and adding a new file to dir1. At the same time, we wish to leave open the possibility of committing additional minor changes to the current commit in order to address any bugs or issues that might arise.
In essence what we want to do is start a new branch for the new feature. This is performed in two steps:
-
Use the git branch <name> command to generate a new branch reference
git branch Feature

tree -ra -L 2 --charset ascii
. |-- .gitignore |-- .git | |-- refs | |-- objects | |-- logs | |-- info | |-- index | |-- hooks | |-- HEAD | |-- description | |-- config | |-- COMMIT_EDITMSG | `-- branches |-- file1 `-- dir1 |-- f.tmp `-- file2 8 directories, 9 filesgit reflog
76572a7 HEAD@{0}: commit: Modified file2, added .gitignore 88ce744 HEAD@{1}: commit: Modified file1 and added file2 (in dir1) ec937de HEAD@{2}: commit (initial): Initial repo and added file1
-
Use the git checkout <name> command to move the HEAD to the tip of this new branch (Feature).
git checkout Feature
Switched to branch 'Feature' M dir1/file2

tree -ra -L 2 --charset ascii
. |-- .gitignore |-- .git | |-- refs | |-- objects | |-- logs | |-- info | |-- index | |-- hooks | |-- HEAD | |-- description | |-- config | |-- COMMIT_EDITMSG | `-- branches |-- file1 `-- dir1 |-- f.tmp `-- file2 8 directories, 9 filesgit reflog
76572a7 HEAD@{0}: checkout: moving from master to Feature 76572a7 HEAD@{1}: commit: Modified file2, added .gitignore 88ce744 HEAD@{2}: commit: Modified file1 and added file2 (in dir1) ec937de HEAD@{3}: commit (initial): Initial repo and added file1
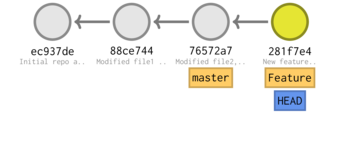
Now if we make and commit a change (such as an edit to file1 and an addition of file3 within dir1), we will be operating on a separate branch
echo 'b' >> file1 echo 'File 3' > dir1/file3 git add . git commit -m 'New feature'
[Feature 281f7e4] New feature 3 files changed, 3 insertions(+) create mode 100644 dir1/file3
tree -ra -L 2 --charset ascii
.
|-- .gitignore
|-- .git
| |-- refs
| |-- objects
| |-- logs
| |-- info
| |-- index
| |-- hooks
| |-- HEAD
| |-- description
| |-- config
| |-- COMMIT_EDITMSG
| `-- branches
|-- file1
`-- dir1
|-- f.tmp
|-- file3
`-- file2
8 directories, 10 files
git reflog
281f7e4 HEAD@{0}: commit: New feature
76572a7 HEAD@{1}: checkout: moving from master to Feature
76572a7 HEAD@{2}: commit: Modified file2, added .gitignore
88ce744 HEAD@{3}: commit: Modified file1 and added file2 (in dir1)
ec937de HEAD@{4}: commit (initial): Initial repo and added file1
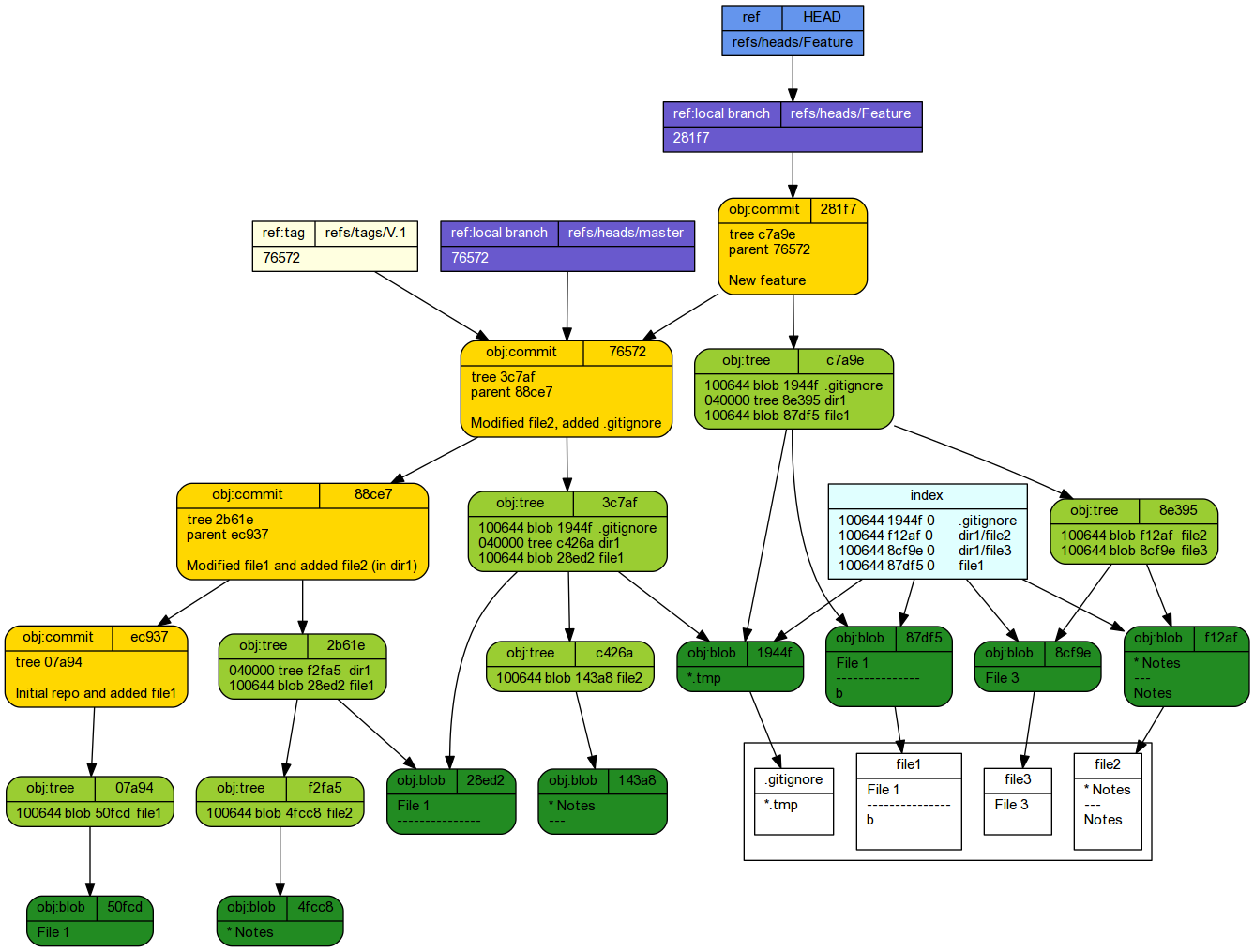
So we can now continue to develop the Feature branch. But what if we now decided that we wanted to make a change to the master branch (perhaps addressing a bug or issue).
- Switch over to the master branch
git checkout master
Switched to branch 'master'

tree -ra -L 2 --charset ascii
. |-- .gitignore |-- .git | |-- refs | |-- objects | |-- logs | |-- info | |-- index | |-- hooks | |-- HEAD | |-- description | |-- config | |-- COMMIT_EDITMSG | `-- branches |-- file1 `-- dir1 |-- f.tmp `-- file2 8 directories, 9 filesgit reflog
76572a7 HEAD@{0}: checkout: moving from Feature to master 281f7e4 HEAD@{1}: commit: New feature 76572a7 HEAD@{2}: checkout: moving from master to Feature 76572a7 HEAD@{3}: commit: Modified file2, added .gitignore 88ce744 HEAD@{4}: commit: Modified file1 and added file2 (in dir1) ec937de HEAD@{5}: commit (initial): Initial repo and added file1
-
Make the necessary changes to the files and commit them on the master branch
echo ' a bug fix' >> file1 git add . git commit -m 'Bug fix in file1'
[master b8a3859] Bug fix in file1 1 file changed, 1 insertion(+)

tree -ra -L 2 --charset ascii
. |-- .gitignore |-- .git | |-- refs | |-- objects | |-- logs | |-- info | |-- index | |-- hooks | |-- HEAD | |-- description | |-- config | |-- COMMIT_EDITMSG | `-- branches |-- file1 `-- dir1 |-- f.tmp `-- file2 8 directories, 9 filesgit reflog
b8a3859 HEAD@{0}: commit: Bug fix in file1 76572a7 HEAD@{1}: checkout: moving from Feature to master 281f7e4 HEAD@{2}: commit: New feature 76572a7 HEAD@{3}: checkout: moving from master to Feature 76572a7 HEAD@{4}: commit: Modified file2, added .gitignore 88ce744 HEAD@{5}: commit: Modified file1 and added file2 (in dir1) ec937de HEAD@{6}: commit (initial): Initial repo and added file1
We could simultaneously make additional modifications to the Feature branch just by simply checking out the Feature branch and commiting those modifications.
git checkout Feature echo ' a modification' >> dir1/file3 git add . git commit -m 'Feature complete'
Switched to branch 'Feature' [Feature fe72fa0] Feature complete 1 file changed, 1 insertion(+)
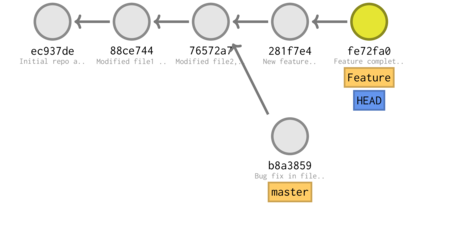
tree -ra -L 2 --charset ascii
.
|-- .gitignore
|-- .git
| |-- refs
| |-- objects
| |-- logs
| |-- info
| |-- index
| |-- hooks
| |-- HEAD
| |-- description
| |-- config
| |-- COMMIT_EDITMSG
| `-- branches
|-- file1
`-- dir1
|-- f.tmp
|-- file3
`-- file2
8 directories, 10 files
git reflog
fe72fa0 HEAD@{0}: commit: Feature complete
281f7e4 HEAD@{1}: checkout: moving from master to Feature
b8a3859 HEAD@{2}: commit: Bug fix in file1
76572a7 HEAD@{3}: checkout: moving from Feature to master
281f7e4 HEAD@{4}: commit: New feature
76572a7 HEAD@{5}: checkout: moving from master to Feature
76572a7 HEAD@{6}: commit: Modified file2, added .gitignore
88ce744 HEAD@{7}: commit: Modified file1 and added file2 (in dir1)
ec937de HEAD@{8}: commit (initial): Initial repo and added file1
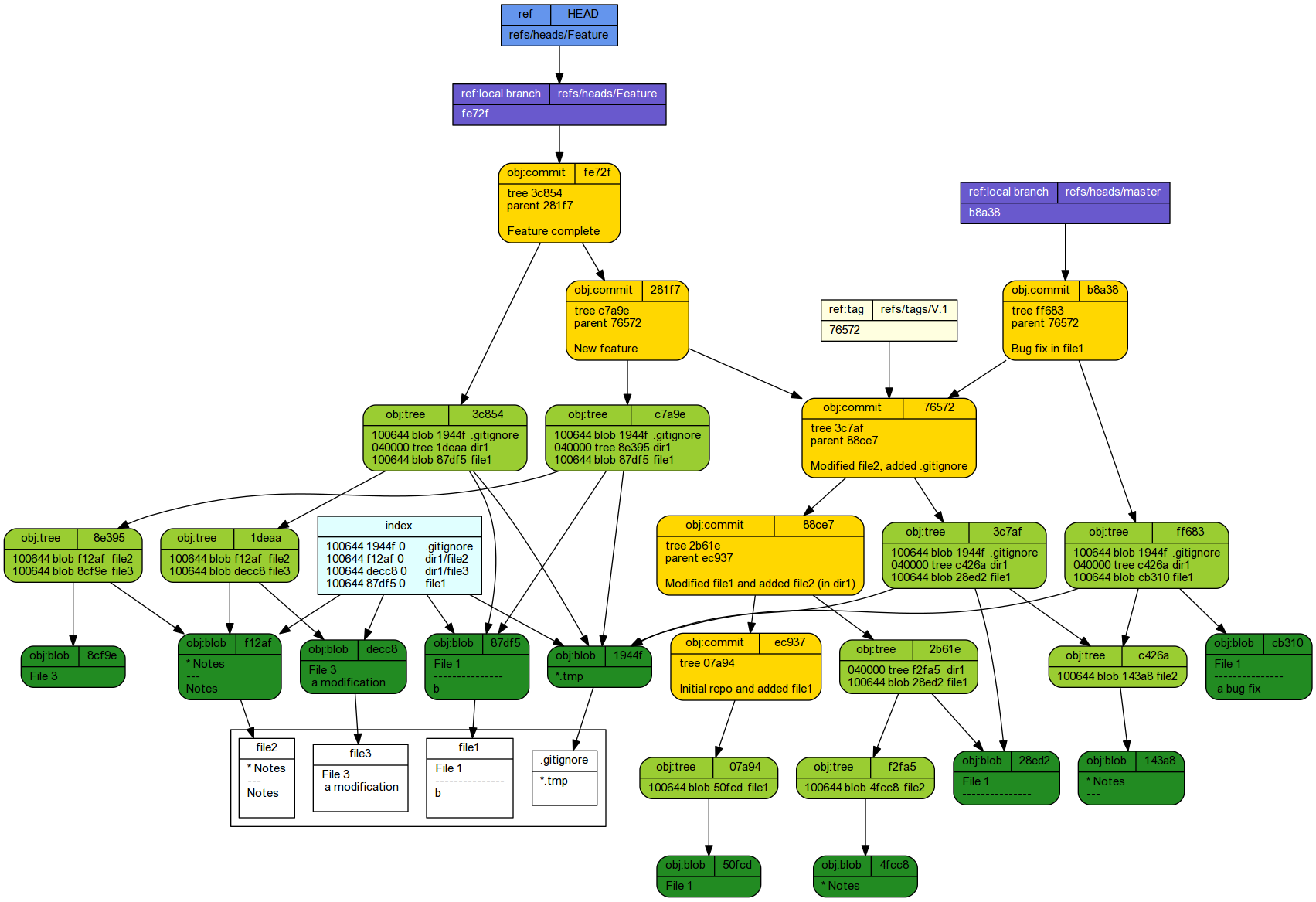
Finally, (if we are satisfied that Feature is stable and complete), we might like to introduce these changes into the master branch so that they become a part of the main project base. This operation is called a merge and is completed with the git merge <branch> command where <branch> is the name of the branch you want to merge the current branch (that pointed to by HEAD) with. Typically we want to merge the non-master branch with the master branch. Therefore we must be checkout the master branch before merging.
git checkout master git merge Feature
Switched to branch 'master' Auto-merging file1 CONFLICT (content): Merge conflict in file1 Automatic merge failed; fix conflicts and then commit the result.
Hmmm. It appears that there is a conflict. If we explore the a git diff, we will see that on the master and Feature branchs have incompatible changes.
git status
On branch master You have unmerged paths. (fix conflicts and run "git commit") (use "git merge --abort" to abort the merge) Changes to be committed: modified: dir1/file2 new file: dir1/file3 Unmerged paths: (use "git add <file>..." to mark resolution) both modified: file1
git diff master Feature
diff --git a/dir1/file2 b/dir1/file2 index 143a8bb..f12af0a 100644 --- a/dir1/file2 +\n ++ b/dir1/file2 @@ -1,2 +1,3 @@ * Notes --- +\n Notes diff --git a/dir1/file3 b/dir1/file3 +\n ew file mode 100644 index 0000000..decc8f3 --- /dev/null +\n ++ b/dir1/file3 @@ -0,0 +1,2 @@ +\n File 3 +\n a modification diff --git a/file1 b/file1 index cb3102f..87df5b1 100644 --- a/file1 +\n ++ b/file1 @@ -1,3 +1,3 @@ File 1 --------------- - a bug fix +\n b
git cat-file -p master^:file1
File 1 ---------------
git cat-file -p master:file1
File 1 --------------- a bug fix
git cat-file -p Feature:file1
File 1 --------------- b
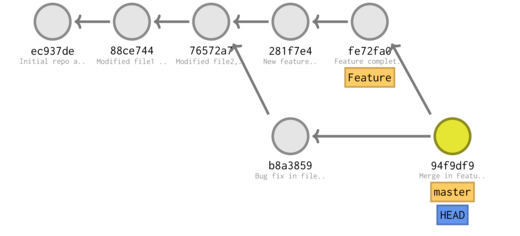
git checkout master^ file1 git add . git commit -m 'Merge in Feature'
[master 94f9df9] Merge in Feature
tree -ra -L 2 --charset ascii
.
|-- .gitignore
|-- .git
| |-- refs
| |-- ORIG_HEAD
| |-- objects
| |-- logs
| |-- info
| |-- index
| |-- hooks
| |-- HEAD
| |-- description
| |-- config
| |-- COMMIT_EDITMSG
| `-- branches
|-- file1
`-- dir1
|-- f.tmp
|-- file3
`-- file2
8 directories, 11 files
git reflog
94f9df9 HEAD@{0}: commit (merge): Merge in Feature
b8a3859 HEAD@{1}: checkout: moving from Feature to master
fe72fa0 HEAD@{2}: commit: Feature complete
281f7e4 HEAD@{3}: checkout: moving from master to Feature
b8a3859 HEAD@{4}: commit: Bug fix in file1
76572a7 HEAD@{5}: checkout: moving from Feature to master
281f7e4 HEAD@{6}: commit: New feature
76572a7 HEAD@{7}: checkout: moving from master to Feature
76572a7 HEAD@{8}: commit: Modified file2, added .gitignore
88ce744 HEAD@{9}: commit: Modified file1 and added file2 (in dir1)
ec937de HEAD@{10}: commit (initial): Initial repo and added file1
git log --graph --decorate --oneline
* 94f9df9 (HEAD -> master) Merge in Feature |\ | * fe72fa0 (Feature) Feature complete | * 281f7e4 New feature * | b8a3859 Bug fix in file1 |/ * 76572a7 (tag: V.1) Modified file2, added .gitignore * 88ce744 Modified file1 and added file2 (in dir1) * ec937de Initial repo and added file1
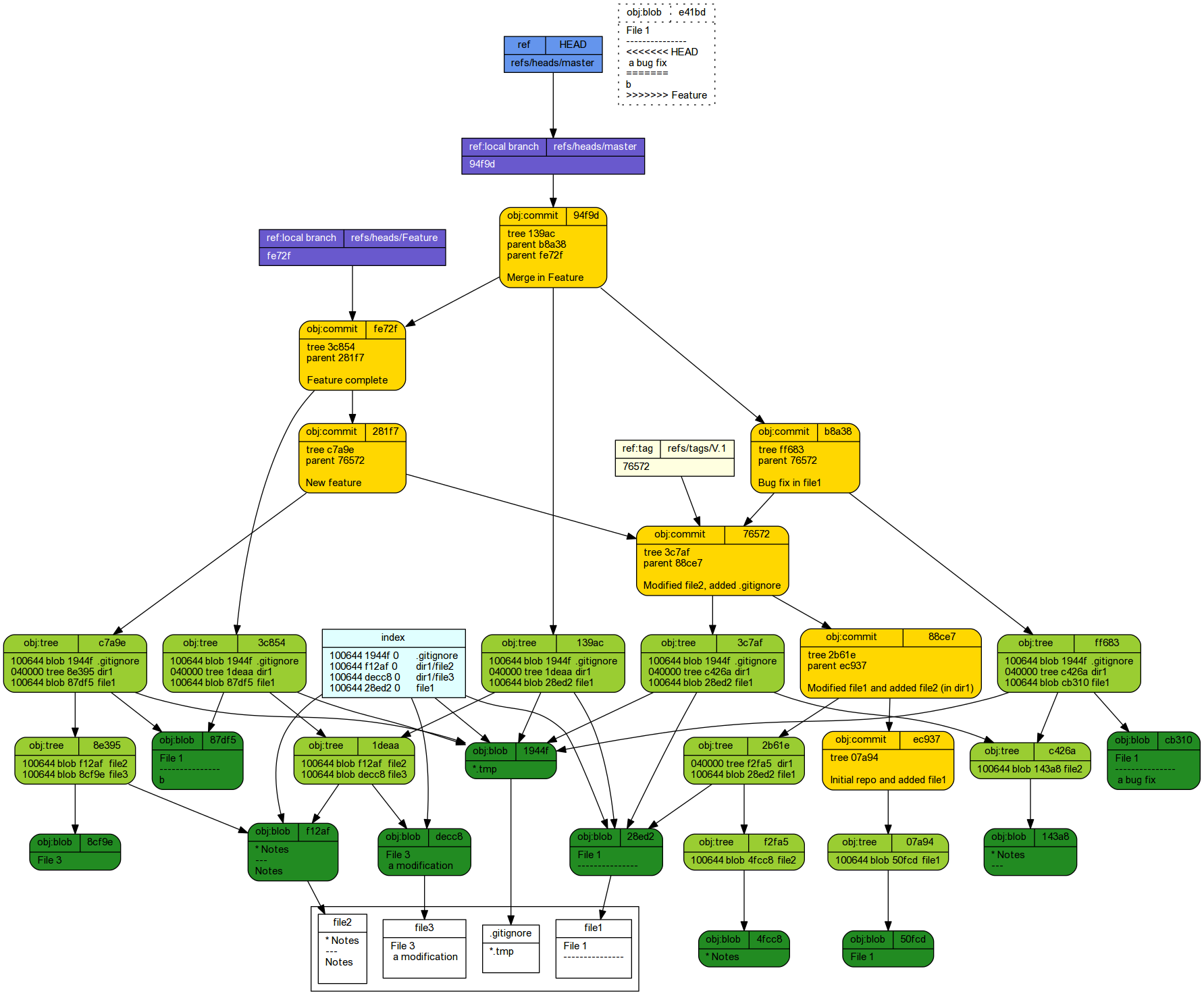
If the bug fix is relatively small, it might be worth considering rebasing into the main master branch to prevent the history becoming overly complex and messy to follow.
git branch -d Feature
Deleted branch Feature (was fe72fa0).
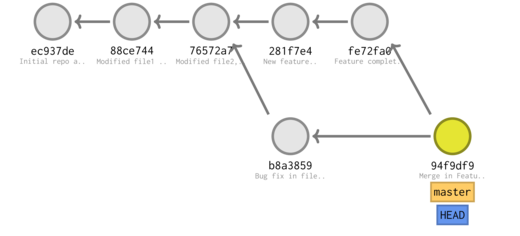
tree -ra -L 2 --charset ascii
.
|-- .gitignore
|-- .git
| |-- refs
| |-- ORIG_HEAD
| |-- objects
| |-- logs
| |-- info
| |-- index
| |-- hooks
| |-- HEAD
| |-- description
| |-- config
| |-- COMMIT_EDITMSG
| `-- branches
|-- file1
`-- dir1
|-- f.tmp
|-- file3
`-- file2
8 directories, 11 files
git reflog
94f9df9 HEAD@{0}: commit (merge): Merge in Feature
b8a3859 HEAD@{1}: checkout: moving from Feature to master
fe72fa0 HEAD@{2}: commit: Feature complete
281f7e4 HEAD@{3}: checkout: moving from master to Feature
b8a3859 HEAD@{4}: commit: Bug fix in file1
76572a7 HEAD@{5}: checkout: moving from Feature to master
281f7e4 HEAD@{6}: commit: New feature
76572a7 HEAD@{7}: checkout: moving from master to Feature
76572a7 HEAD@{8}: commit: Modified file2, added .gitignore
88ce744 HEAD@{9}: commit: Modified file1 and added file2 (in dir1)
ec937de HEAD@{10}: commit (initial): Initial repo and added file1
git log --graph --decorate --oneline
* 94f9df9 (HEAD -> master) Merge in Feature |\ | * fe72fa0 Feature complete | * 281f7e4 New feature * | b8a3859 Bug fix in file1 |/ * 76572a7 (tag: V.1) Modified file2, added .gitignore * 88ce744 Modified file1 and added file2 (in dir1) * ec937de Initial repo and added file1
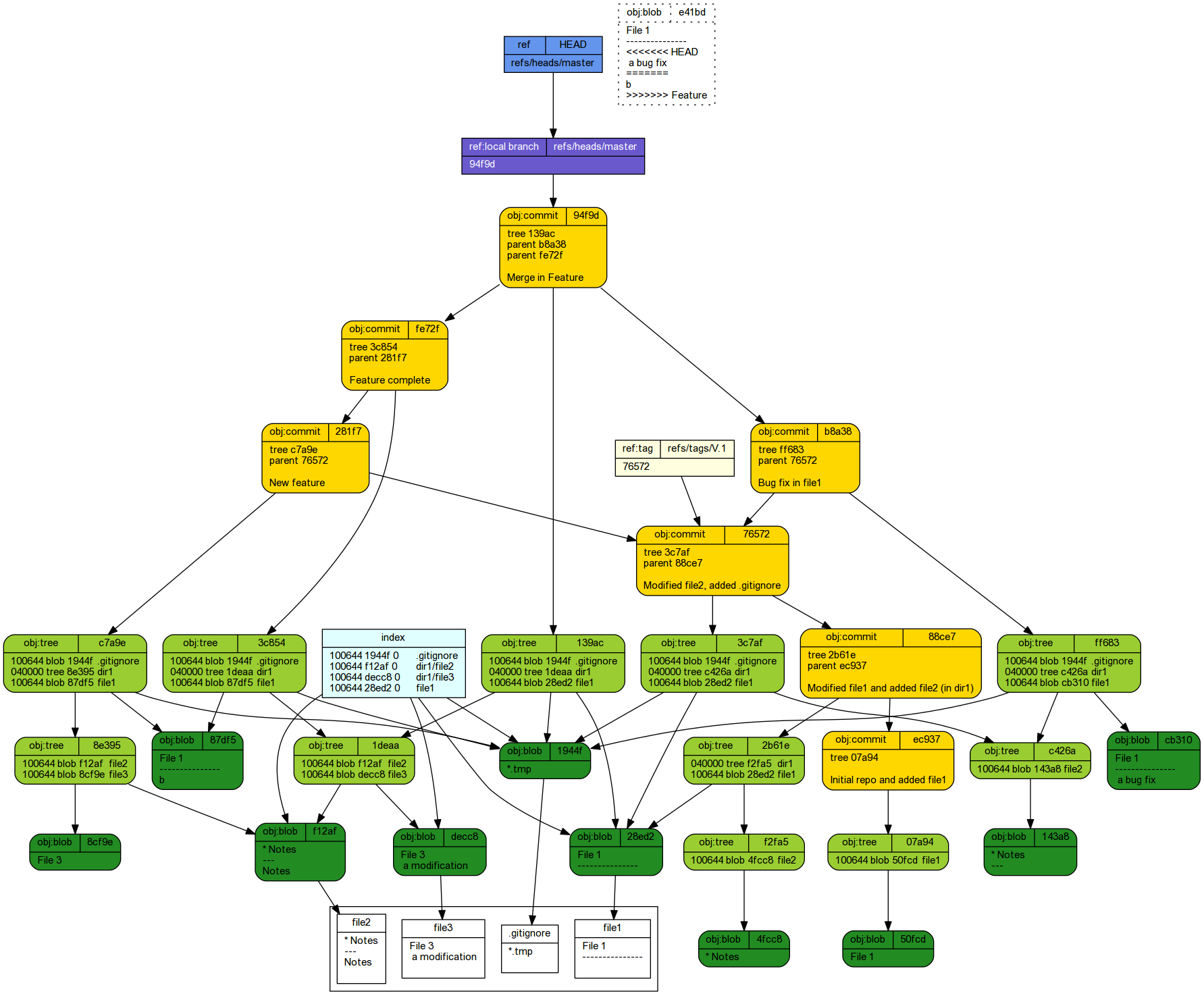
Undoing (rolling back) changes
One of the real strengths of a versioning system is the ability to roll back to a previous state when changes have been found to introduce undesirable or unintended consequences. There are also multiple different stages from which to roll back. For example, do we want to revert from committed states or just unstage a file or files.
To illustrate the various ways to roll back within a repository, we will start by rolling back to the state of the repository
prior to the demonstration on branching. This state is associated with commit 76572.
This repository contains three commits and has the following workspace:
tree -ra -L 2 --charset ascii
.
|-- .gitignore
|-- .git
| |-- refs
| |-- ORIG_HEAD
| |-- objects
| |-- logs
| |-- info
| |-- index
| |-- hooks
| |-- HEAD
| |-- description
| |-- config
| |-- COMMIT_EDITMSG
| `-- branches
|-- file1
`-- dir1
|-- f.tmp
|-- file3
`-- file2
8 directories, 11 files
However, the current state contains a bunch of commits associated with the branching and merge demonstration.
Furthermore, when we look at the reflog, we will notice that there are multiple records associated with commit 76572.
One of these is the checkout to create the stalk for a new branch.
git reflog
94f9df9 HEAD@{0}: commit (merge): Merge in Feature
b8a3859 HEAD@{1}: checkout: moving from Feature to master
fe72fa0 HEAD@{2}: commit: Feature complete
281f7e4 HEAD@{3}: checkout: moving from master to Feature
b8a3859 HEAD@{4}: commit: Bug fix in file1
76572a7 HEAD@{5}: checkout: moving from Feature to master
281f7e4 HEAD@{6}: commit: New feature
76572a7 HEAD@{7}: checkout: moving from master to Feature
76572a7 HEAD@{8}: commit: Modified file2, added .gitignore
88ce744 HEAD@{9}: commit: Modified file1 and added file2 (in dir1)
ec937de HEAD@{10}: commit (initial): Initial repo and added file1
If we explore the git log we can see that there was a tag associated with the original 76572 commit.
Therefore, to avoid confusion, we will attempt to rollback using the tag rather than commit sha1.
git log --graph --decorate --oneline
* 94f9df9 (HEAD -> master) Merge in Feature |\ | * fe72fa0 Feature complete | * 281f7e4 New feature * | b8a3859 Bug fix in file1 |/ * 76572a7 (tag: V.1) Modified file2, added .gitignore * 88ce744 Modified file1 and added file2 (in dir1) * ec937de Initial repo and added file1
If, like me, you have completed the previous sections, we can roll back to this state by:
cd ~/tmp/Repo1 git reset --hard V.1 git clean -qfdx git reflog expire --expire-unreachable=now --all git gc --prune=now
76572. Normally, we would not erase the repositories history quite so aggressively - you never know
when you will want to reverse your decision. The above git commands well as others will be described in details in the following sections.
mkdir ~/tmp/Repo1 cd ~/tmp/RepoA git init echo 'File 1' > file1 git add file1 git commit -m 'Initial repo and added file1' echo '---------------' >> file1 mkdir dir1 echo '* Notes' > dir1/file2 git add file1 dir1/file2 git commit -m 'Modified file1 and added file2 (in dir1)' echo '---' > dir1/file2 echo 'temp' > dir1/f.tmp echo '*.tmp' > .gitignore git add . git commit -m 'Modified file2, added .gitignore'
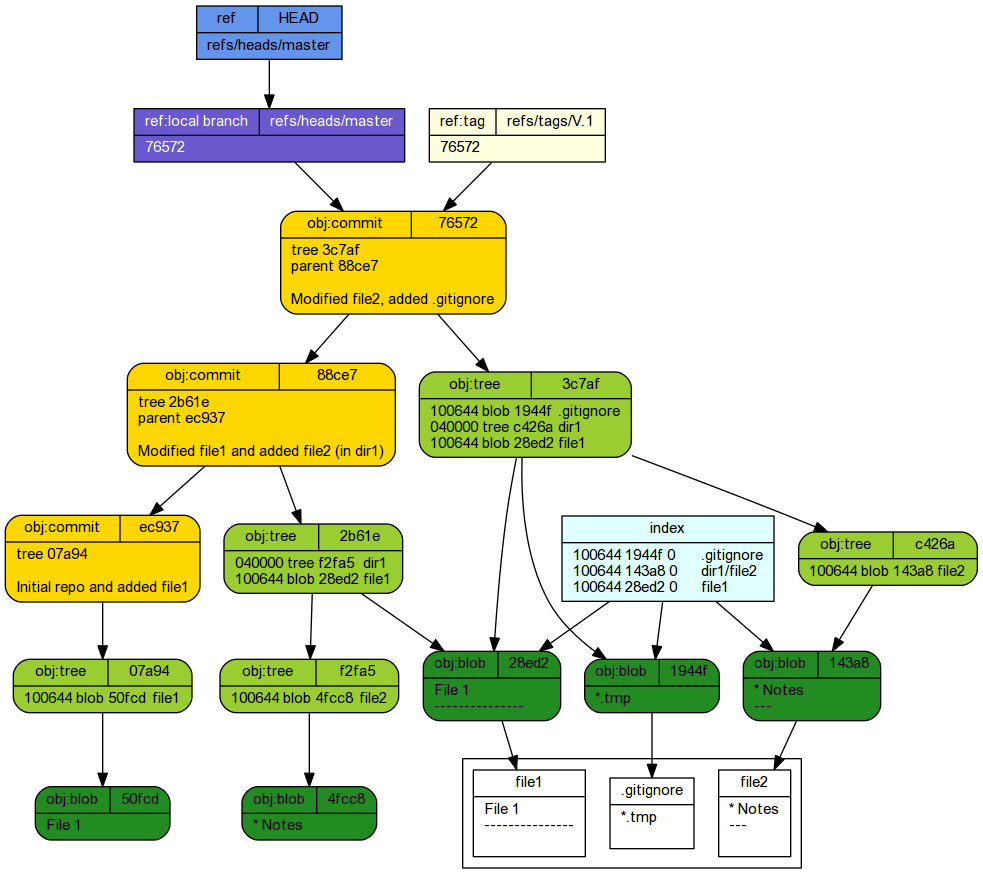
tree -ra -L 2 --charset ascii
.
|-- .gitignore
|-- .git
| |-- refs
| |-- packed-refs
| |-- ORIG_HEAD
| |-- objects
| |-- logs
| |-- info
| |-- index
| |-- hooks
| |-- HEAD
| |-- description
| |-- config
| |-- COMMIT_EDITMSG
| `-- branches
|-- file1
`-- dir1
`-- file2
8 directories, 10 files
git reflog
76572a7 HEAD@{0}: checkout: moving from master to Feature
76572a7 HEAD@{1}: commit: Modified file2, added .gitignore
88ce744 HEAD@{2}: commit: Modified file1 and added file2 (in dir1)
ec937de HEAD@{3}: commit (initial): Initial repo and added file1
git log --graph --decorate --oneline
* 76572a7 (HEAD -> master, tag: V.1) Modified file2, added .gitignore * 88ce744 Modified file1 and added file2 (in dir1) * ec937de Initial repo and added file1
The above diagram shows that both HEAD and master point at the same stage (all three files). Again, remember that the SHA-1 has values will be different in your repo so in the following, you will need to use the SHA value that corresponds to the item in your list.
With additional commits and activity, the above schematic will rapidly become very busy and complex. As a result, we will now switch to a simpler schematic that focuses only on the commits and references thereof (HEAD, master and branches).
Recall that a git repository comprises multiple levels in which changes are recorded:
- There is the Workspace (which is essentially the actual files and folders that you directly edit).
- There is the Staging area (or index which is a record of which files are next to be committed).
- There is the Local repository (the actual commits).
- And finally, three is the remote repository (a remote store of commits).
| Action | Command | Notes |
|---|---|---|
| Commit level | ||
Undo to a particular local commit |
git reset --soft <commit> | HEAD is moved to the nominated <commit>. IT DOES NOT alter index or the workspace |
| Roll back to the the previous commit |
git reset --hard <commit> | Resets the Index and Workspace |
Roll back over the last two commits |
git reset --hard HEAD~2 | Roll back over the last two commits |
| Inspect an old commit |
git checkout <commit> | moves the HEAD and modifies the workspace to reflect its state at <commit> |
| Roll back the changes introduced by commit so that a new commit resembles a previous state |
git revert HEAD | Creates a new commit that reverses the changes introduced by the last commit. Revert creates a new revision history that adds onto existing history and is therefore safe to use on a branch that has been pushed to a remote. |
Now lets say we wanted to roll back to the state before we added .gitignore and modified dir1/file2.
That is, we want to roll-back to commit 88ce7.
We have three main choices:
- reset - this allows us to remove all commits back to a nominated commit. Resetting is a irreversible process as it totally removes commits from the history. A reset should only ever be used if you are sure you want to permanently remove the changes introduced via one or more commits. A reset should never be performed on a branch that exists in a remote repository
- revert - this allows us to skip the most recent commit. That is, a revert rolls back to a previous commit and then apply that state to a new commit. Unlike a reset, all commits remain safely in the git history and can target a single commit.
- branch - this allows us to safely take the project (or part of the project) in an experimental direction that might involve dramatic deviations in files without interrupting the main thread of the project. At some point, if the new direction proves useful, the changes can be merged back into the main branch. We will expore branching in the section on branching.
Normally we would not perform all three. Rather, we would select the most appropriate one
depending on the context and goal. Nevertheless, this is a tutorial and therefore we will
perform all three. In order to ensure that we start from the same point for each demonstration,
prior to each demonstration, we will aggressively reset the repository back to the state it was at commit 88ce7.
Reset
Soft reset
When we perform a soft reset, we move the head to the nominated commit, but the workspace is unchanged.
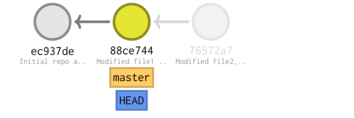
cd ~/tmp/Repo1 git reset --soft 88ce7
Hard reset
When we perform a hard reset, we not only move the head to the nominated commit, but the workspace is altered to reflect the workspace that existed when that commit was originally performed.
cd ~/tmp/Repo1 git reset --hard V.1 git clean -qfdx git reflog expire --expire-unreachable=now --all git gc --prune=now
cd ~/tmp/Repo1 git reset --hard 88ce7
HEAD is now at 88ce744 Modified file1 and added file2 (in dir1)
If we now explore the reflog, we see that the head is now at 88ce7.
cd ~/tmp/Repo1 git reflog
88ce744 HEAD@{0}: reset: moving to 88ce7
76572a7 HEAD@{1}: reset: moving to V.1
88ce744 HEAD@{2}: reset: moving to 88ce7
76572a7 HEAD@{3}: checkout: moving from master to Feature
76572a7 HEAD@{4}: commit: Modified file2, added .gitignore
88ce744 HEAD@{5}: commit: Modified file1 and added file2 (in dir1)
ec937de HEAD@{6}: commit (initial): Initial repo and added file1
cd ~/tmp/Repo1 git log --graph --oneline --decorate
* 88ce744 (HEAD -> master) Modified file1 and added file2 (in dir1) * ec937de Initial repo and added file1
tree -ra -L 2 --charset ascii
.
|-- .git
| |-- refs
| |-- packed-refs
| |-- ORIG_HEAD
| |-- objects
| |-- logs
| |-- info
| |-- index
| |-- hooks
| |-- HEAD
| |-- description
| |-- config
| |-- COMMIT_EDITMSG
| `-- branches
|-- file1
`-- dir1
`-- file2
8 directories, 9 files
git ls-files
dir1/file2 file1
If we now make a change (such as a change to file1 and adding file3) and commit, it would be as if any commits after
88ce7 had never occurred.
cd ~/tmp/Repo1 echo 'End' > file1 echo 'File3' >> dir1/file3 git add file1 dir1/file3 git commit -m 'Modified file1 and added file3'
[master 1dafad1] Modified file1 and added file3 2 files changed, 2 insertions(+), 2 deletions(-) create mode 100644 dir1/file3
cd ~/tmp/Repo1 git reflog
1dafad1 HEAD@{0}: commit: Modified file1 and added file3
88ce744 HEAD@{1}: reset: moving to 88ce7
76572a7 HEAD@{2}: reset: moving to V.1
88ce744 HEAD@{3}: reset: moving to 88ce7
76572a7 HEAD@{4}: checkout: moving from master to Feature
76572a7 HEAD@{5}: commit: Modified file2, added .gitignore
88ce744 HEAD@{6}: commit: Modified file1 and added file2 (in dir1)
ec937de HEAD@{7}: commit (initial): Initial repo and added file1
cd ~/tmp/Repo1 git log --graph --oneline --decorate
* 1dafad1 (HEAD -> master) Modified file1 and added file3 * 88ce744 Modified file1 and added file2 (in dir1) * ec937de Initial repo and added file1
tree -ra -L 2 --charset ascii
.
|-- .git
| |-- refs
| |-- packed-refs
| |-- ORIG_HEAD
| |-- objects
| |-- logs
| |-- info
| |-- index
| |-- hooks
| |-- HEAD
| |-- description
| |-- config
| |-- COMMIT_EDITMSG
| `-- branches
|-- file1
`-- dir1
|-- file3
`-- file2
8 directories, 10 files
git ls-files
dir1/file2 dir1/file3 file1
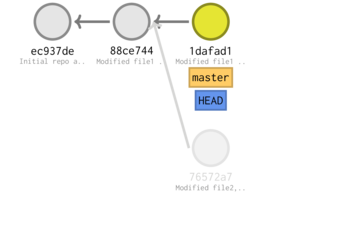
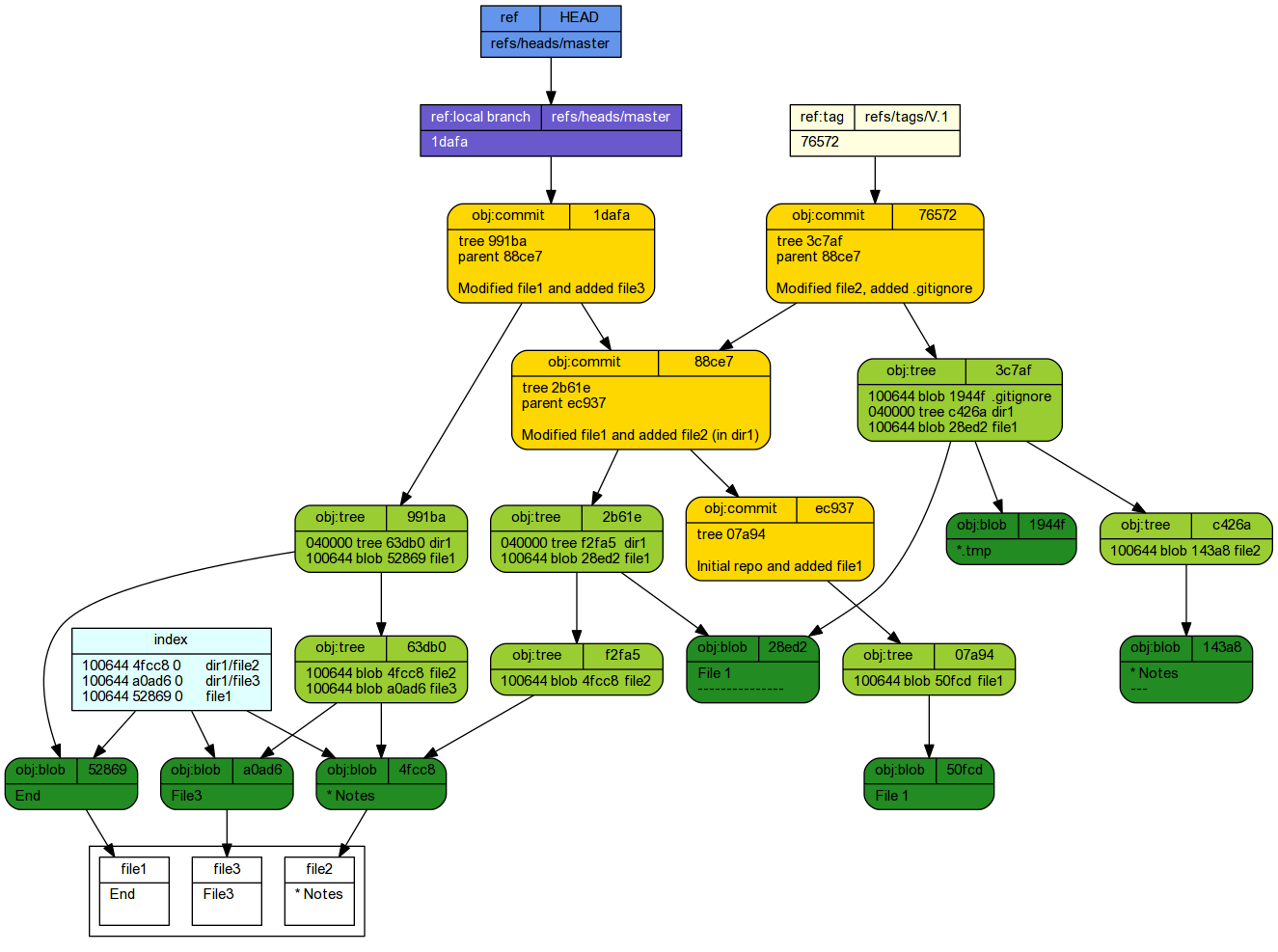
Revert
cd ~/tmp/Repo1 git reset --hard V.1 git clean -qfdx git reflog expire --expire-unreachable=now --all git gc --prune=now
Revert generates a new commit that removes the changes that were introduced by one or more of the most recent commits.
Note, it does not revert to a particular commit, but rather undoes a commit.
So, to roll back to 88ce7 (the second last commit), we just have to revert the last commit (HEAD).
cd ~/tmp/Repo1 git revert HEAD
[master c30c900] Revert "Modified file2, added .gitignore" 2 files changed, 2 deletions(-) delete mode 100644 .gitignore
git reflog
c30c900 HEAD@{0}: revert: Revert "Modified file2, added .gitignore"
76572a7 HEAD@{1}: reset: moving to 88ce7
76572a7 HEAD@{2}: reset: moving to V.1
88ce744 HEAD@{3}: reset: moving to 88ce7
76572a7 HEAD@{4}: checkout: moving from master to Feature
76572a7 HEAD@{5}: commit: Modified file2, added .gitignore
88ce744 HEAD@{6}: commit: Modified file1 and added file2 (in dir1)
ec937de HEAD@{7}: commit (initial): Initial repo and added file1
cd ~/tmp/Repo1 git log --graph --oneline --decorate
* c30c900 (HEAD -> master) Revert "Modified file2, added .gitignore" * 76572a7 (tag: V.1) Modified file2, added .gitignore * 88ce744 Modified file1 and added file2 (in dir1) * ec937de Initial repo and added file1
tree -ra -L 2 --charset ascii
.
|-- .git
| |-- refs
| |-- packed-refs
| |-- ORIG_HEAD
| |-- objects
| |-- logs
| |-- info
| |-- index
| |-- hooks
| |-- HEAD
| |-- description
| |-- config
| |-- COMMIT_EDITMSG
| `-- branches
|-- file1
`-- dir1
`-- file2
8 directories, 9 files
If we list the files that are part of the repo:
git ls-files
dir1/file2 file1
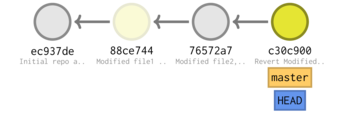
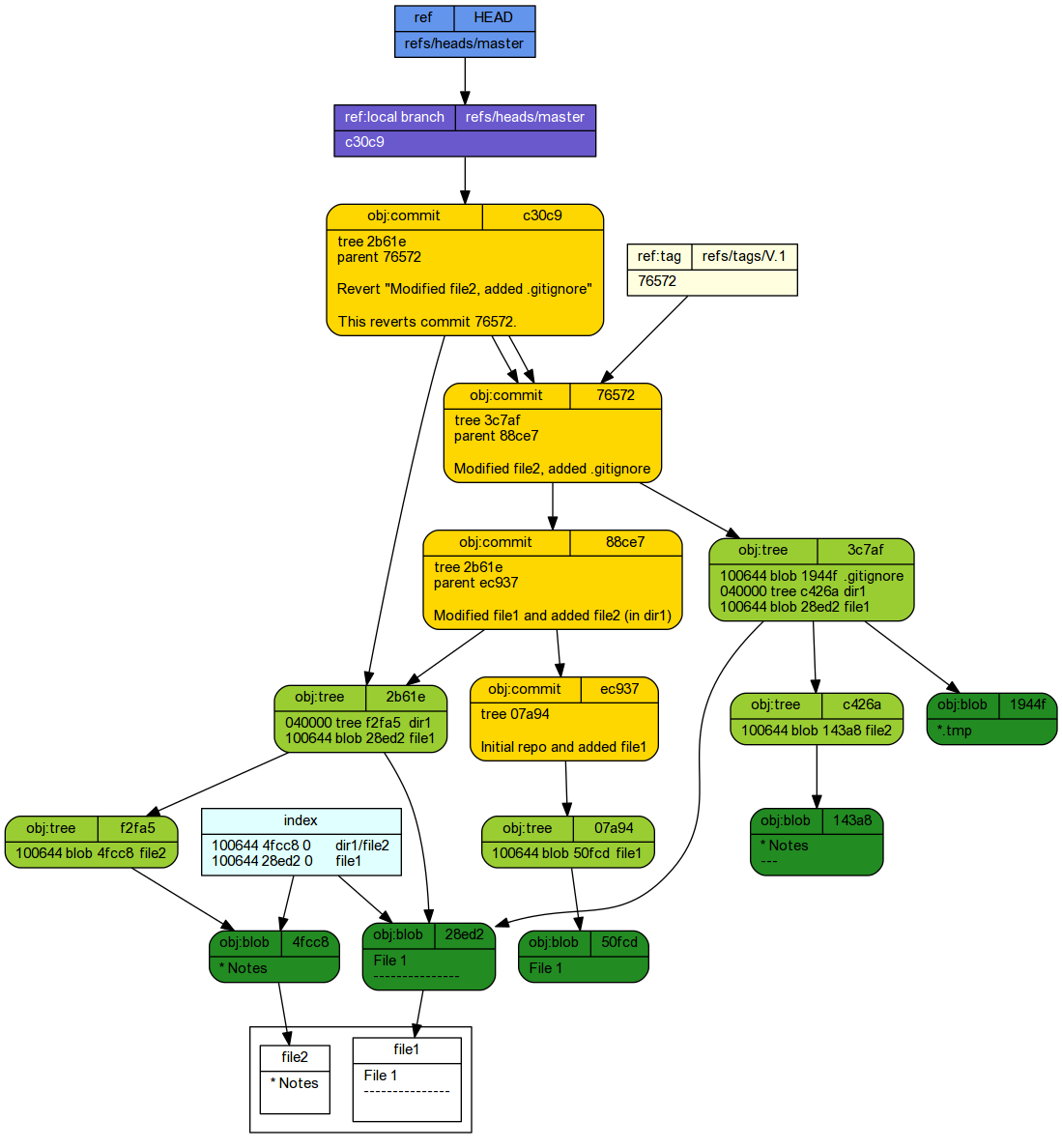
If we had actually wanted to roll back to commit ec937,
then we could do so by issuing the above followed by:
cd ~/tmp/Repo1 git reset --hard V.1 git clean -qfdx git reflog expire --expire-unreachable=now --all git gc --prune=now
cd ~/tmp/Repo1 git revert --no-commit HEAD
git revert --no-commit HEAD~1 git commit -m 'Rolled back'
[master 9466da9] Rolled back 3 files changed, 4 deletions(-) delete mode 100644 .gitignore delete mode 100644 dir1/file2
git reflog
9466da9 HEAD@{0}: commit: Rolled back
76572a7 HEAD@{1}: reset: moving to 88ce7
76572a7 HEAD@{2}: reset: moving to V.1
88ce744 HEAD@{3}: reset: moving to 88ce7
76572a7 HEAD@{4}: checkout: moving from master to Feature
76572a7 HEAD@{5}: commit: Modified file2, added .gitignore
88ce744 HEAD@{6}: commit: Modified file1 and added file2 (in dir1)
ec937de HEAD@{7}: commit (initial): Initial repo and added file1
cd ~/tmp/Repo1 git log --graph --oneline --decorate
* 9466da9 (HEAD -> master) Rolled back * 76572a7 (tag: V.1) Modified file2, added .gitignore * 88ce744 Modified file1 and added file2 (in dir1) * ec937de Initial repo and added file1
tree -ra -L 2 --charset ascii
. |-- .git | |-- refs | |-- packed-refs | |-- ORIG_HEAD | |-- objects | |-- logs | |-- info | |-- index | |-- hooks | |-- HEAD | |-- description | |-- config | |-- COMMIT_EDITMSG | `-- branches `-- file1 7 directories, 8 files
If we list the files that are part of the repo:
git ls-files
file1
git diff 9466 88ce7
diff --git a/dir1/file2 b/dir1/file2 +\n ew file mode 100644 index 0000000..4fcc8f8 --- /dev/null +\n ++ b/dir1/file2 @@ -0,0 +1 @@ +\n * Notes diff --git a/file1 b/file1 index 50fcd26..28ed245 100644 --- a/file1 +\n ++ b/file1 @@ -1 +1,2 @@ File 1 +\n ---------------
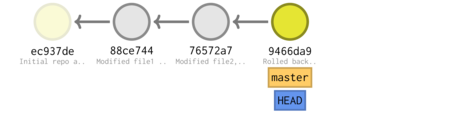
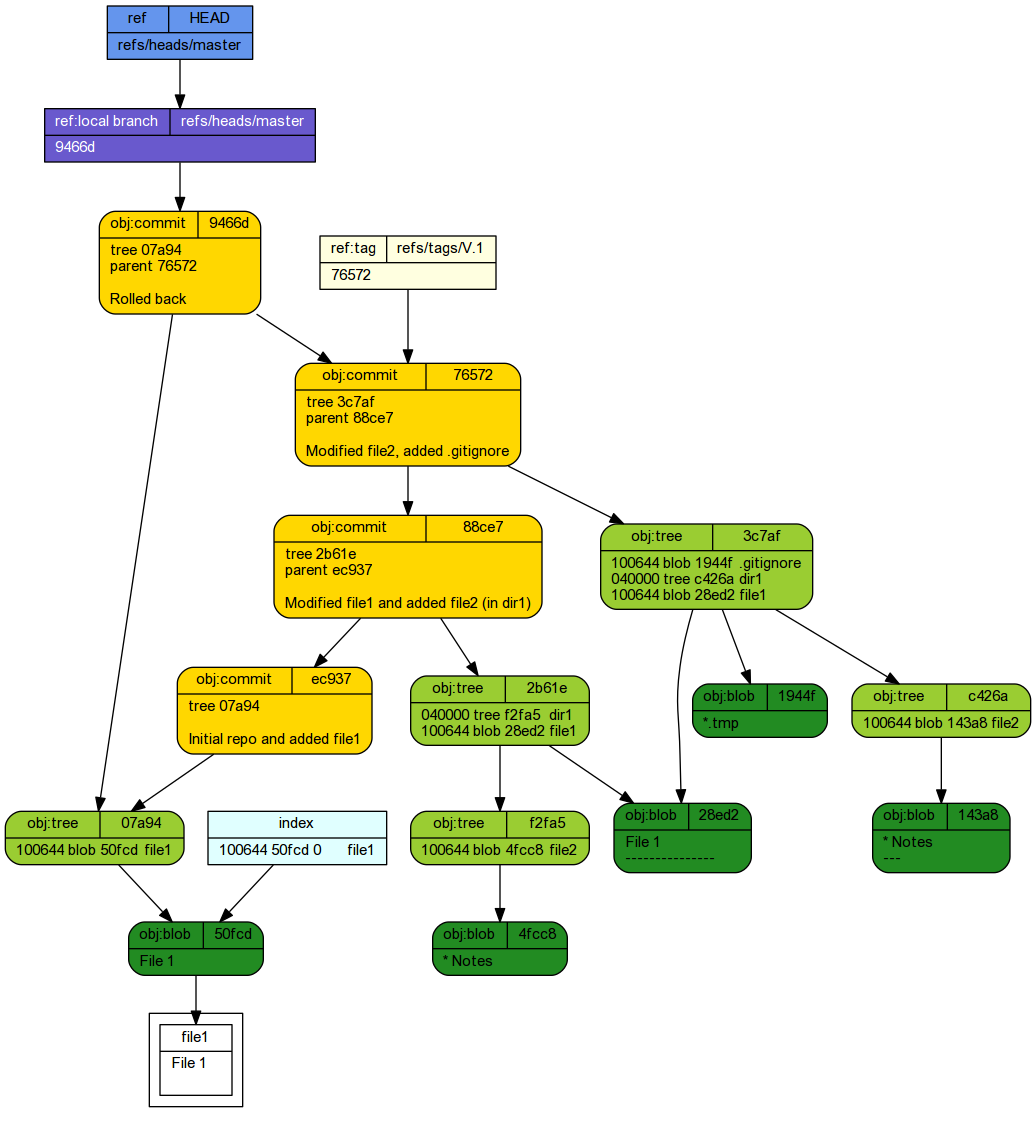
checkout and Branching
cd ~/tmp/Repo1 git reset --hard V.1 git clean -qfdx git reflog expire --expire-unreachable=now --all git gc --prune=now
If we wanted to review the state of files corresponding to commit 88ce7, we could checkout the
code from that commit. This provides a way to travel back in time through your commits and explore the (tracked) files exactly as they were.
cd ~/tmp/Repo1 git checkout 88ce7
Note: checking out '88ce7'. You are in 'detached HEAD' state. You can look around, make experimental changes and commit them, and you can discard any commits you make in this state without impacting any branches by performing another checkout. If you want to create a new branch to retain commits you create, you may do so (now or later) by using -b with the checkout command again. Example: git checkout -b <new-branch-name> HEAD is now at 88ce744... Modified file1 and added file2 (in dir1)
tree -ra -L 2 --charset ascii
.
|-- .git
| |-- refs
| |-- packed-refs
| |-- ORIG_HEAD
| |-- objects
| |-- logs
| |-- info
| |-- index
| |-- hooks
| |-- HEAD
| |-- description
| |-- config
| |-- COMMIT_EDITMSG
| `-- branches
|-- file1
`-- dir1
`-- file2
8 directories, 9 files
If we list the files that are part of the repo:
git ls-files
dir1/file2 file1
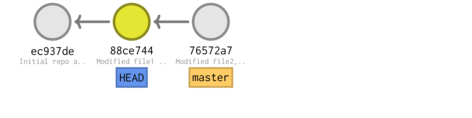
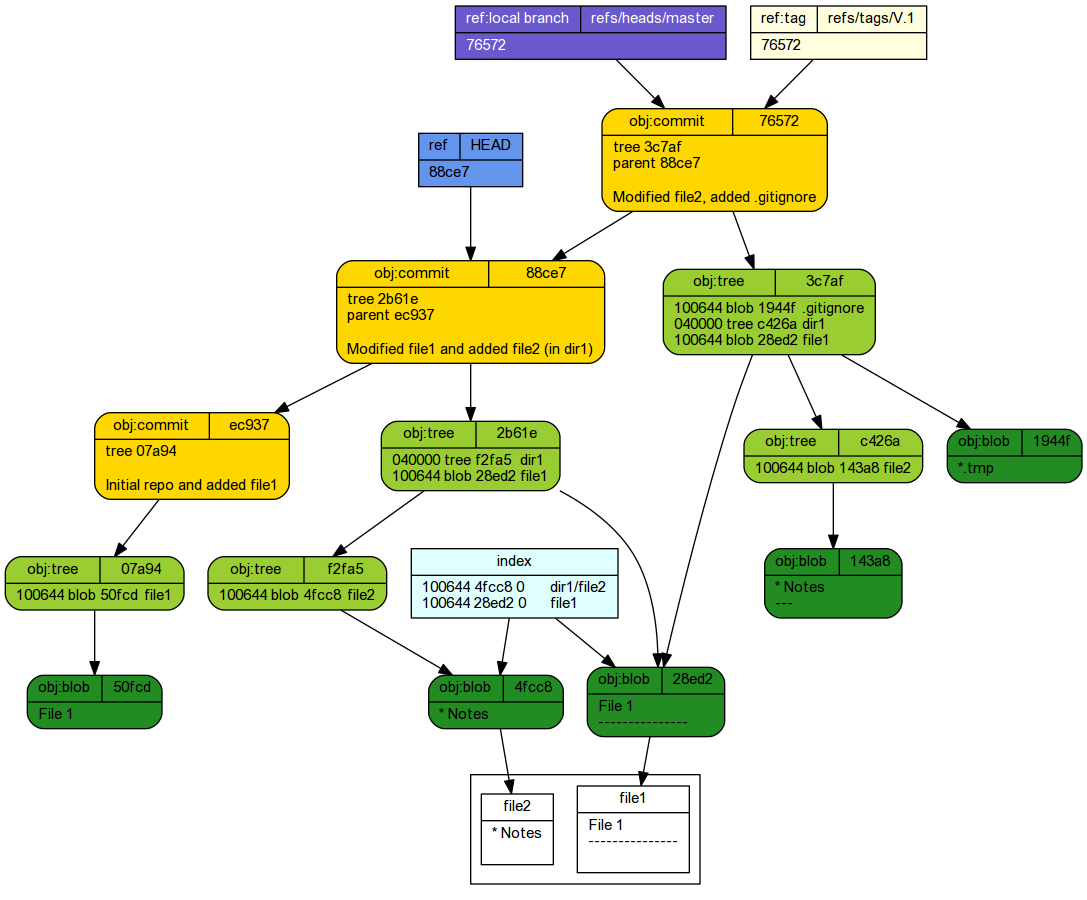
echo 'END' > file3 git add file3 git commit -m 'END added to file3'
[detached HEAD 150c1fb] END added to file3 1 file changed, 1 insertion(+) create mode 100644 file3
git reflog
150c1fb HEAD@{0}: commit: END added to file3
88ce744 HEAD@{1}: checkout: moving from master to 88ce7
76572a7 HEAD@{2}: reset: moving to 88ce7
76572a7 HEAD@{3}: reset: moving to V.1
88ce744 HEAD@{4}: reset: moving to 88ce7
76572a7 HEAD@{5}: checkout: moving from master to Feature
76572a7 HEAD@{6}: commit: Modified file2, added .gitignore
88ce744 HEAD@{7}: commit: Modified file1 and added file2 (in dir1)
ec937de HEAD@{8}: commit (initial): Initial repo and added file1
cd ~/tmp/Repo1 git log --graph --oneline --decorate
* 150c1fb (HEAD) END added to file3 * 88ce744 Modified file1 and added file2 (in dir1) * ec937de Initial repo and added file1
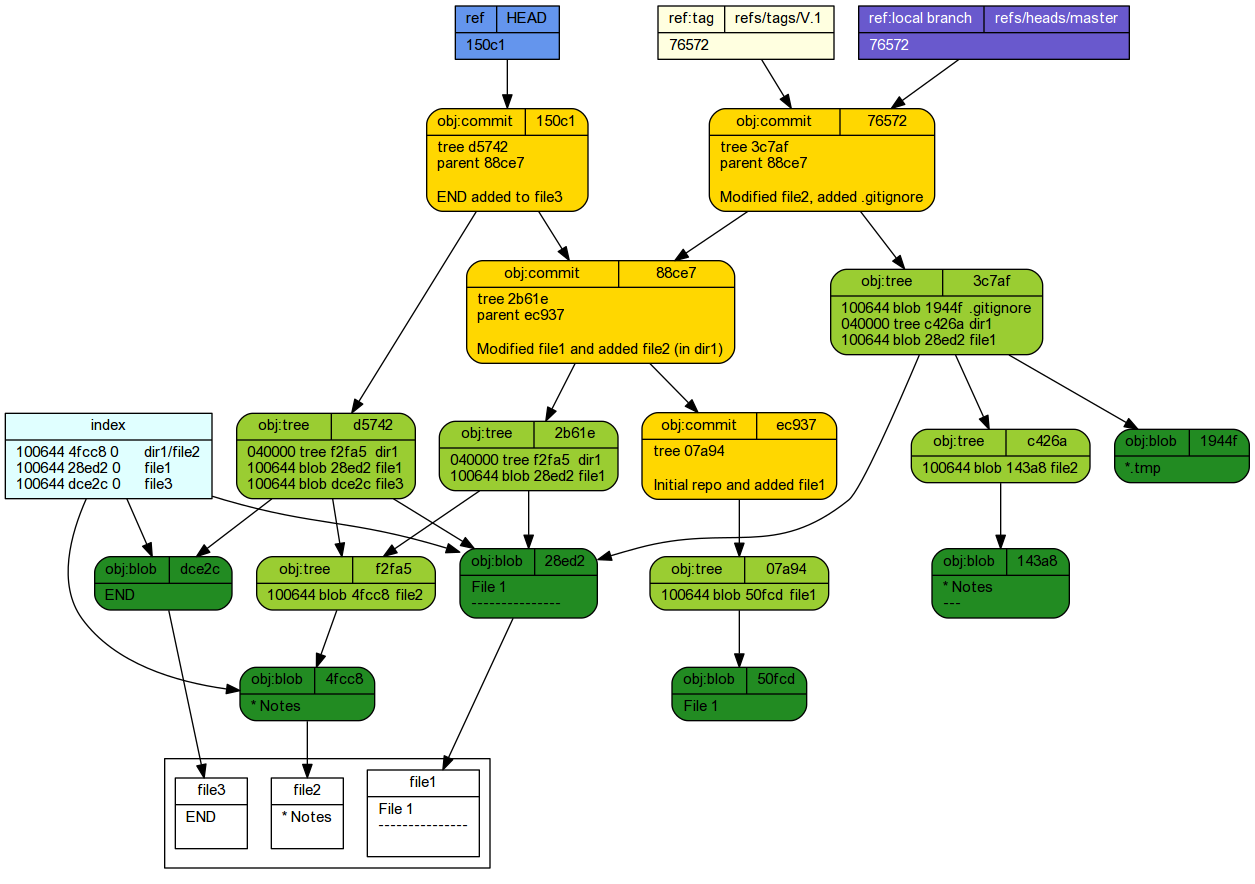
And then checked out the master branch..
git checkout master
Warning: you are leaving 1 commit behind, not connected to any of your branches: 150c1fb END added to file3 If you want to keep it by creating a new branch, this may be a good time o do so with: git branch <new-branch-name> 150c1fb Switched to branch 'master'
git reflog
76572a7 HEAD@{0}: checkout: moving from 150c1fbf5ea921087aa3535fabcdb0bdbab54d43 to master
150c1fb HEAD@{1}: commit: END added to file3
88ce744 HEAD@{2}: checkout: moving from master to 88ce7
76572a7 HEAD@{3}: reset: moving to 88ce7
76572a7 HEAD@{4}: reset: moving to V.1
88ce744 HEAD@{5}: reset: moving to 88ce7
76572a7 HEAD@{6}: checkout: moving from master to Feature
76572a7 HEAD@{7}: commit: Modified file2, added .gitignore
88ce744 HEAD@{8}: commit: Modified file1 and added file2 (in dir1)
ec937de HEAD@{9}: commit (initial): Initial repo and added file1
cd ~/tmp/Repo1 git log --graph --oneline --decorate
* 76572a7 (HEAD -> master, tag: V.1) Modified file2, added .gitignore * 88ce744 Modified file1 and added file2 (in dir1) * ec937de Initial repo and added file1
tree -ra -L 2 --charset ascii
.
|-- .gitignore
|-- .git
| |-- refs
| |-- packed-refs
| |-- ORIG_HEAD
| |-- objects
| |-- logs
| |-- info
| |-- index
| |-- hooks
| |-- HEAD
| |-- description
| |-- config
| |-- COMMIT_EDITMSG
| `-- branches
|-- file1
`-- dir1
`-- file2
8 directories, 10 files
If we list the files that are part of the repo:
git ls-files
.gitignore dir1/file2 file1
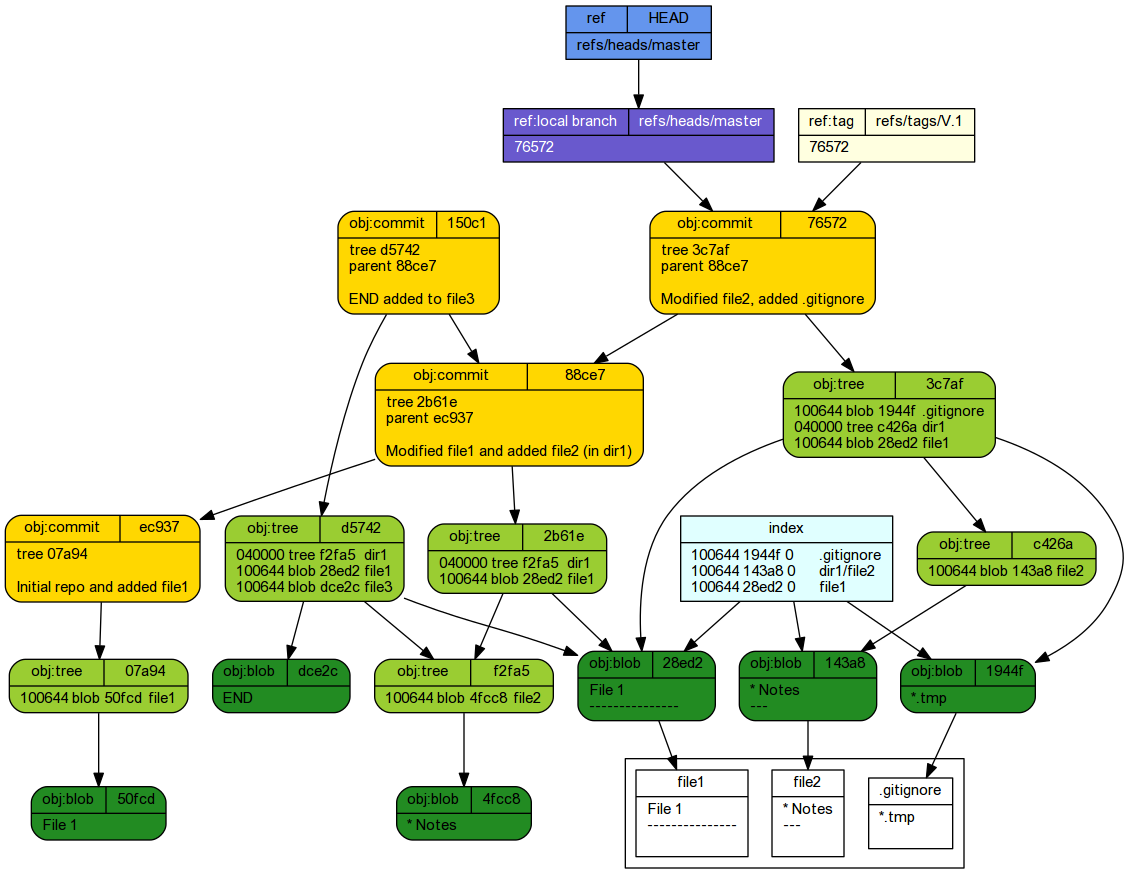
If, having reviewed the state of a commit (by checking it out), we decided that we wanted to roll back to this state and develop further (make additional commits), we are effectively deciding to start a new branch that splits off at that commit. See the section on Branching for more details on how to do that.
Syncing with a remote repository
When a project has multiple contributors, it is typical for there to be a remote repository against which each contributor can exchange their contributions. The remote repository comprises only the .git folder (and its contents), it never has a workspace. Files are never edited directly on the remote repository. Instead, it acts as a constantly available 'master' conduit between all contributors.
A remote repository can be anywhere that you have permission to at least read from. Obviously, if you also want to contribute your local commits to the remote repository, you also need write access to that location. If you entend to collaborate, then obviously the remote repository needs to be in a location that all users can access at any time.
For the purpose of this tutorial, we will create a remote repository that is on the same computer as the above repository that we have been working on. Whilst not the typical situation, it does mean that an external location and account is not necessary to follow along with the tutorial. As previously mentioned, the actual location of the remote repository is almost irrelevant to how you interact with it. Therefore, whether the remote repository is on the same computer or elsewhere in the world makes little difference (other than permissions and connections).
cd ~/tmp/Repo1 git reset --hard V.1 git clean -qfdx git reflog expire --expire-unreachable=now --all git gc --prune=now
Lets start by creating a folder (as a sibling to Repo1) to contain the remote repository before creating a bare remote repository to house our project.
mkdir ~/tmp/RemoteRepo1 cd ~/tmp/RemoteRepo1 git init --bare
Initialized empty Git repository in /home/murray/tmp/RemoteRepo1/
Now that we have a remote repository - albeit empty at this stage - we return to our local repository and declare (add) the location of the remote repository using the git remote add <name> <url> command. In this command, an optional name can be supplied to refer to the remote repository (<name>). The compulsory <url> argument is the address (location) of the remote repository.
cd ~/tmp/Repo1 git remote add origin ~/tmp/RemoteRepo1
To see what this has achieved, we can have a quick look at the .git/config
cd ~/tmp/Repo1 cat .git/config
[core] repositoryformatversion = 0 filemode = true bare = false logallrefupdates = true [remote "origin"] url = /home/murray/tmp/RemoteRepo1 fetch = +refs/heads/*:refs/remotes/origin/*
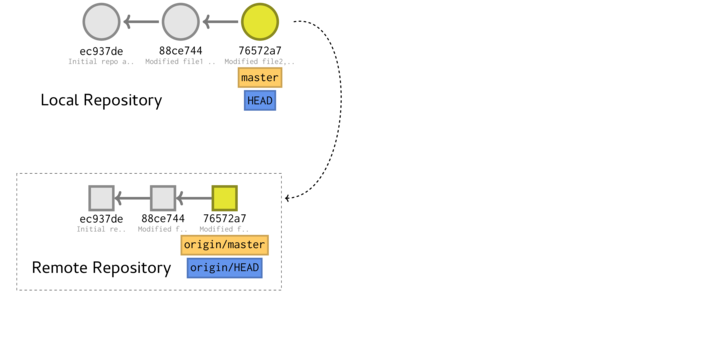
Pushing
Currently the remote repository is empty. We will now push our local commit history to the remote repository. This is achieved via the git push -u <name> <ref> command. Here, <name> is the name of the remote repository ('origin') and <ref> is a reference the head of the commit chain we want to sync.
cd ~/tmp/Repo1 git push -u origin master git reflog
To /home/murray/tmp/RemoteRepo1
* [new branch] master -> master
Branch master set up to track remote branch master from origin.
76572a7 HEAD@{0}: reset: moving to V.1
76572a7 HEAD@{1}: checkout: moving from master to 88ce7
76572a7 HEAD@{2}: reset: moving to 88ce7
76572a7 HEAD@{3}: reset: moving to V.1
88ce744 HEAD@{4}: reset: moving to 88ce7
76572a7 HEAD@{5}: checkout: moving from master to Feature
76572a7 HEAD@{6}: commit: Modified file2, added .gitignore
88ce744 HEAD@{7}: commit: Modified file1 and added file2 (in dir1)
ec937de HEAD@{8}: commit (initial): Initial repo and added file1
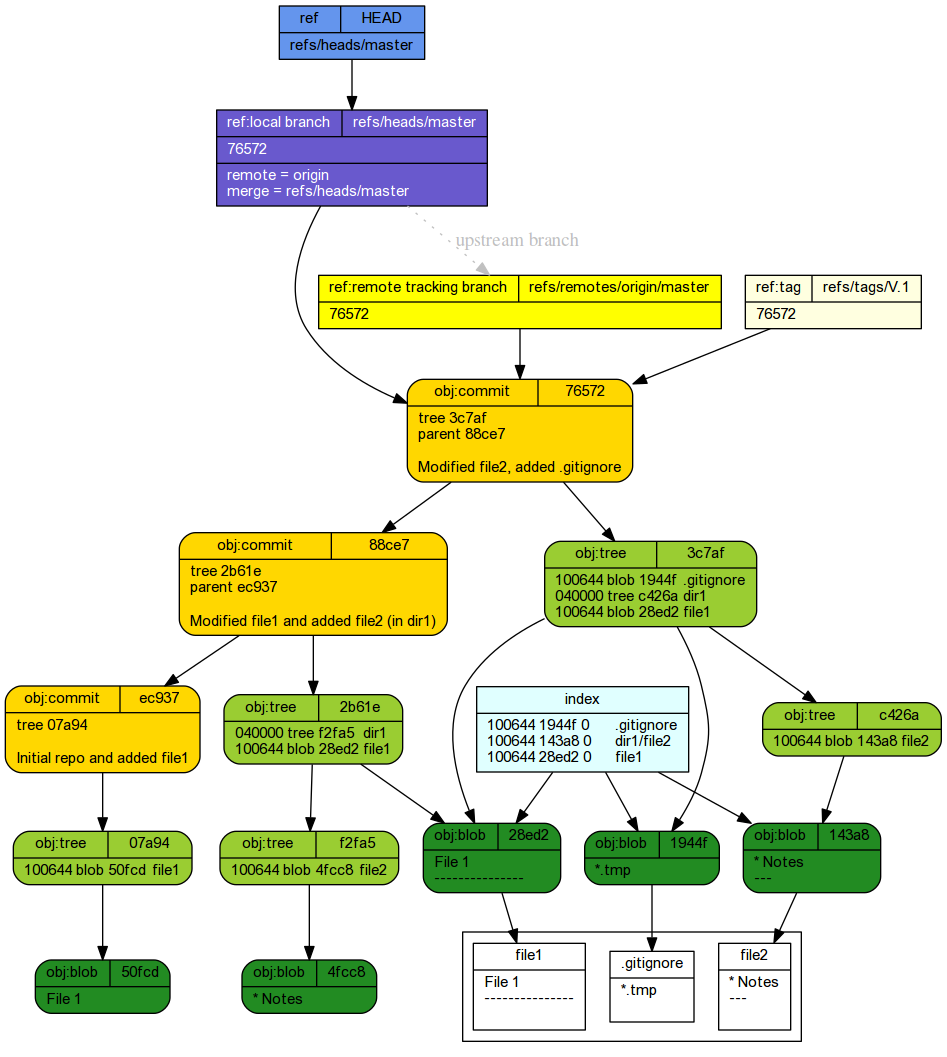
Pulling
Retrieving a commit chain (pulling) from a remote repository is superficially the opposite of pushing. Actually, it is two actions:
- a fetch that retrieves the remote information and uses it to create a branch off your local repository (the name of this branch is made from the name of the remote and the branch that was fetched - e.g. origin/master).
- a merge that merges this branch into the main repository.
cd ~/tmp/Repo1 git pull
Already up-to-date.
To get a better appreciation of how fetching, merging and pulling work, lets clone our repository into yet another local location (thereby mimicking the addition of a collaborator. This collaborator will then make a modification and push their changes back.
cd ~/tmp git clone ~/tmp/RemoteRepo1 MyRepo1
Cloning into 'MyRepo1'... done.
And now for the modification
cd ~/tmp/MyRepo1 echo 'Something else' > file4 git add file4 git commit -m 'Added file4' git push -u origin master
[master bf73dc9] Added file4 1 file changed, 1 insertion(+) create mode 100644 file4 To /home/murray/tmp/RemoteRepo1 76572a7..bf73dc9 master -> master Branch master set up to track remote branch master from origin.
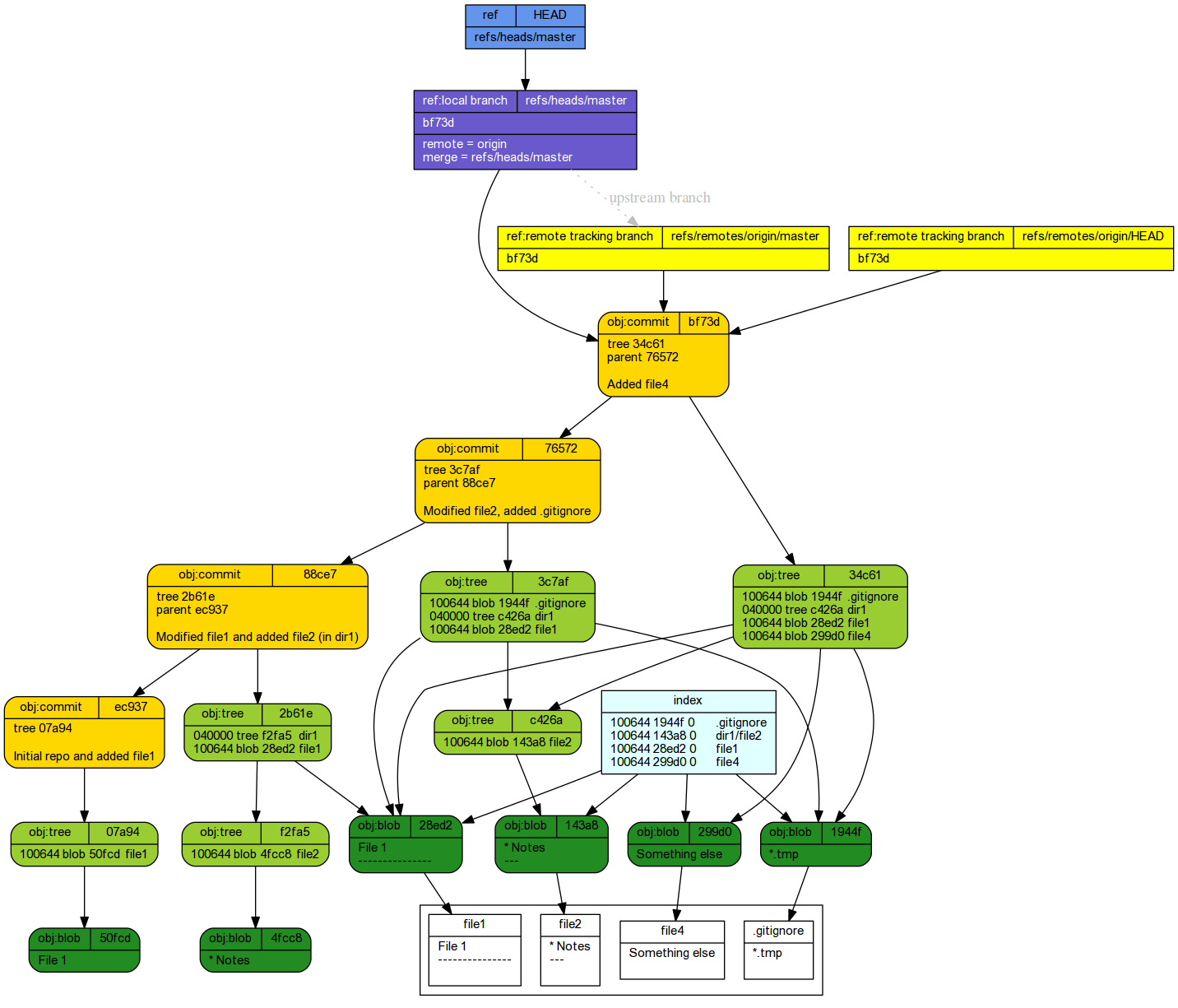
If we now return to our original 'Repo1' local repository (assuming the personal or collaborator 1), our local repository is not up to date with the remote repository (not that we would necessarily know that). Prior to commencing any edits, it is advisable that we fetch (or pull) down any potential updates on the remote repository so that our copy is as close to the remote version before we start. We will fetch using the git fetch command.
cd ~/tmp/Repo1 git fetch
From /home/murray/tmp/RemoteRepo1 76572a7..bf73dc9 master -> origin/master
cd ~/tmp/Repo1 git log --oneline --graph --decorate git reflog
* 76572a7 (HEAD -> master, tag: V.1) Modified file2, added .gitignore
* 88ce744 Modified file1 and added file2 (in dir1)
* ec937de Initial repo and added file1
76572a7 HEAD@{0}: reset: moving to V.1
76572a7 HEAD@{1}: checkout: moving from master to 88ce7
76572a7 HEAD@{2}: reset: moving to 88ce7
76572a7 HEAD@{3}: reset: moving to V.1
88ce744 HEAD@{4}: reset: moving to 88ce7
76572a7 HEAD@{5}: checkout: moving from master to Feature
76572a7 HEAD@{6}: commit: Modified file2, added .gitignore
88ce744 HEAD@{7}: commit: Modified file1 and added file2 (in dir1)
ec937de HEAD@{8}: commit (initial): Initial repo and added file1
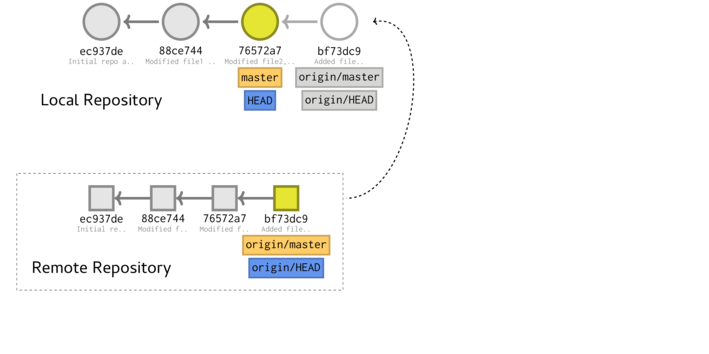
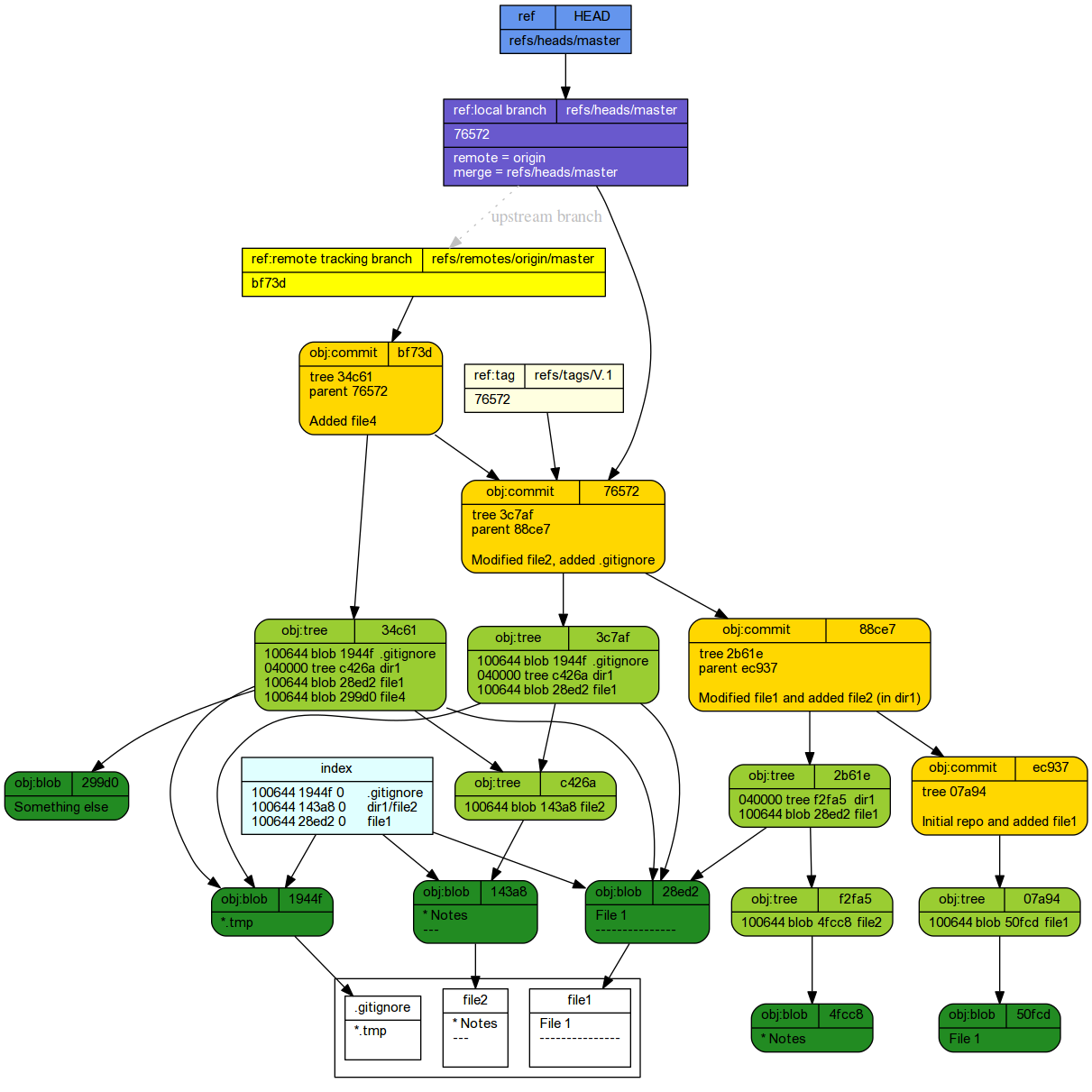
Now we merge this into the master branch.
cd ~/tmp/Repo1 git merge
Updating 76572a7..bf73dc9 Fast-forward file4 | 1 + 1 file changed, 1 insertion(+) create mode 100644 file4
cd ~/tmp/Repo1 git log --oneline --graph --decorate git reflog
* bf73dc9 (HEAD -> master, origin/master) Added file4
* 76572a7 (tag: V.1) Modified file2, added .gitignore
* 88ce744 Modified file1 and added file2 (in dir1)
* ec937de Initial repo and added file1
bf73dc9 HEAD@{0}: merge refs/remotes/origin/master: Fast-forward
76572a7 HEAD@{1}: reset: moving to V.1
76572a7 HEAD@{2}: checkout: moving from master to 88ce7
76572a7 HEAD@{3}: reset: moving to 88ce7
76572a7 HEAD@{4}: reset: moving to V.1
88ce744 HEAD@{5}: reset: moving to 88ce7
76572a7 HEAD@{6}: checkout: moving from master to Feature
76572a7 HEAD@{7}: commit: Modified file2, added .gitignore
88ce744 HEAD@{8}: commit: Modified file1 and added file2 (in dir1)
ec937de HEAD@{9}: commit (initial): Initial repo and added file1
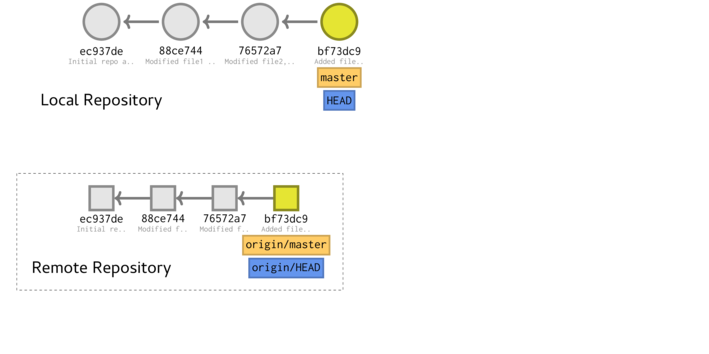
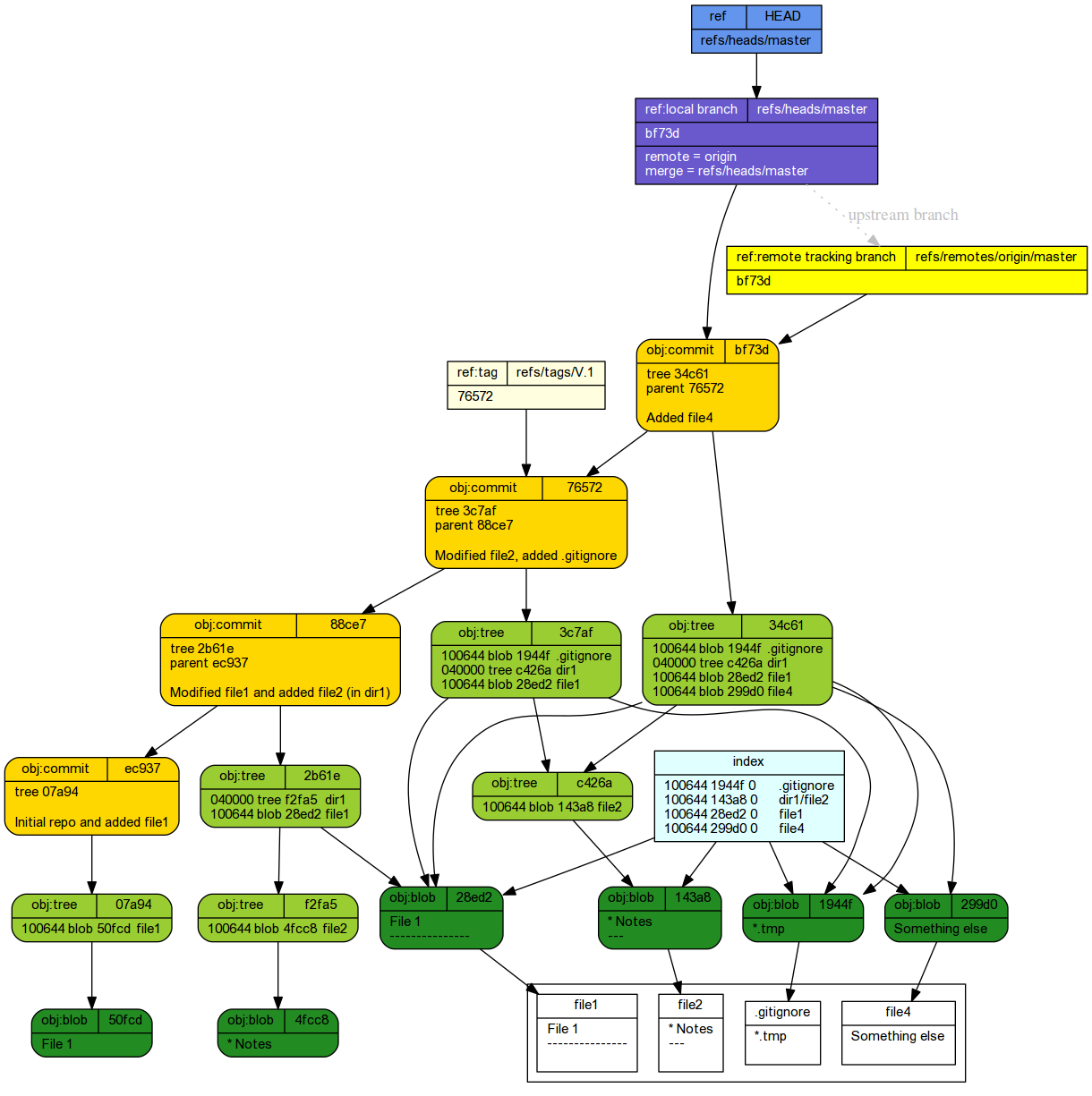
Resolving conflicts
Git within emacs and RStudio
For this part we will create a new repository (I will call it Rrepo) and it will also be in ~/tmp. I will repeat many of the steps above, yet with a more R centric focus. The point will be to demonstrate interacting with git via emacs (using magit) and RStudio.
Note for RStudio, to work with a repository, it is necessary to create project. When doing so, a number of RStudio specific files (not related to git at all) are created - most of which are also added to the .gitignore file (and therefore not included in the repository). The R project file (ending in an extension of .Rproj) stores some project specific settings, yet is also required by RStudio to recognise that the folder is associated with a git repository. These various files are of no consequence to git or emacs.
Initial setup
Prior to beginning you will need:
- A github, gitlab or bitbucket account (if you wish to push, pull and clone external repositories)
- git installed on your computer (goto https://git-scm.com/downloads).
There are two ways to associate a project with a git repository:
- Create a new empty project (in a new folder) and indicate that this should also create a git repository
- Create a project from an existing git repository
- Select New Project from the Project dropdown

- Select New Directory followed by Empty Project

- You need to nominate a new folder name and a path into which this folder (project) is
to be created. Lets call the Directory name Rrepo within the tmp subdirectory in your home directory.
Also make sure the Create a git repository checkbox is ticked.

- Click the Create Project button
- Click the Create Project button
- Select New Project from the Project dropdown
- Select Version Control followed by Git

- You will need to supply the URL for the github (or gitlab, bitbucket etc),
repository. We also need to supply a folder name and path for the new local project that will be associated with the remote repository.
Lets call the Directory name Rrepo within the tmp subdirectory in your home directory.

- Click the Create Project button
Navigate to the ~/tmp folder and create a new folder called Rrepo. Then within emacs, issue the following command.
M-x magit-init
Adding files
Now we need to add some files. Obviously we could create any files here we will start by adding a single R script with a very small amount of content.
Add a new R script and enter a couple of lines of code and save the R script as analysis.R

Navigate to the ~/tmp folder and create a new folder called Rrepo. Then within emacs, create a file called analysis.R and populate it with the following contents:
C-x C-f analysis.R

C-c C-s
Git status
To monitor the status of files within a git repository, goto the Git tab

The main starting point for magit is:
C-x g
Staging (adding) files to the local git repository
Click the checkbox next to each of the files you wish to Stage

From the magit status (C-x g), move the cursor to either a single file (to stage just that file) or to Untracked files (to stage them all) and enter one of the following:
| Command | Description |
|---|---|
| s | stage file |
| S | stage all files. |
| u | unstage file |
| U | unstage all files. |
Committing files to the local git repository
Click the Commit button. This will bring up the Review Changes window.
This window will list the files to be committed, the diff (what has changed in
the selected file between the current staged version and the previous committed version (if one exists),
and a box for entering a Commit message. You should always enter a Commit message. Then click the Commit button.

From the magit status (C-x g), move the cursor to either a single file (to commit just that file) or to Staged files (to commit them all) and enter c followed by another c.
| Command | Description |
|---|---|
| c | commit changes |
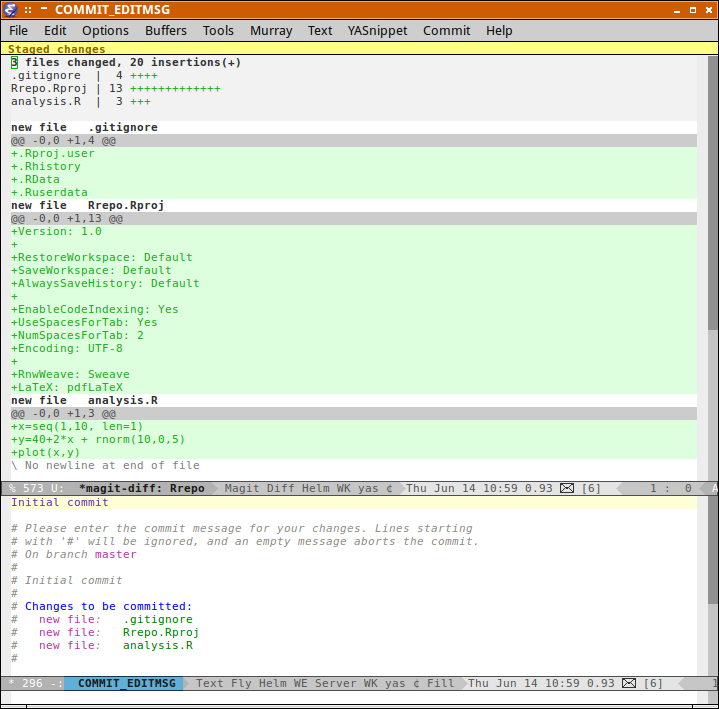
Additional commits (following content changes)
To demonstrate how to perform some of the typical functions, we are going to need to make and commit multiple changes to the analysis.R file. Using a similar workflow to the above instructions for staging and committing, perform the following:
- Modify and commit (with a commit message of 'Added summary for x') the analysis.R file to the following:
x = seq(1, 10, len = 1) y = 40 + 2 * x + rnorm(10, 0, 5) plot(x, y) summary(x)
- Modify and commit (with a commit message of 'Added summary for y') the analysis.R file to the following:
x = seq(1, 10, len = 1) y = 40 + 2 * x + rnorm(10, 0, 5) plot(x, y) summary(x) summary(y)
Viewing the log
Now that we have multiple commits, we might want to review the log of the repositories history.
From the Git panel, click the clock (History). This will bring up View Changes dialog box.

To top panel displays the git log (commits ordered from latest to oldest)
The bottom panel displays information about the files associated with the currently selected commit.
For one of the files (in this case there is only a single file), it indicates the difference between the current commit
and the previous commit (red background indicates a deletion and green background and addition).
From the magit status (C-x g), enter the letter 'l' followed by 'l'.
| Command | Description |
|---|---|
| l | show log |
| Command | Description |
|---|---|
| l | log current |
| o | log other |
| h | log HEAD |
| b | log all branches |
| a | log all references |
| r | reflog current |
| O | reflog other |
| H | reflog HEAD |
This will show the magit-log. Commits are ordered from latest to oldest.
Pressing RETURN on a commit will bring up the magit-revision in which the commit info and diff log is displayed for each file associated with the commit.
Alternatively, from magit-status, enter the letter 'l' followed by 'r'. This will bring up the magit-reflog.

Adding tags
Tagging a commit allows us to flag a certain point in the codes evolution as a milestone or version. This makes it easier to identify that commit from amongst the many other commits.
There are two types of tags:
As far as I know, there is no way to add tags directly from the RStudio GUI. It can be performed from the pure git commands in a shell however.
From the Git panel, click the cog icon and select Shell from the dropdown menu.

A terminal window will appear into which you can enter the following:
git tag -a 'V.1' -m 'Version 1'
The -m indicates the message associated with the commit
If you then revisit the History or Diff, you will notice that the 'V.1' tag has been added to the HEAD commit.
You can then close any lingering windows (not the main RStudio window obviously).
From the magit status (C-x g), put the cursor on a commit (HEAD) and enter the letter 't', ENTER over the --annotate option to activate it and then 't' again.
- When prompted, provide a name for the tag. Lets call it 'V.1' (spaces are not permitted).
- With RETURN again to place the tag on master (the default).
- Finally, provide a message to associate with the tag ('Version 1' in this case). Finalize by C-c C-c
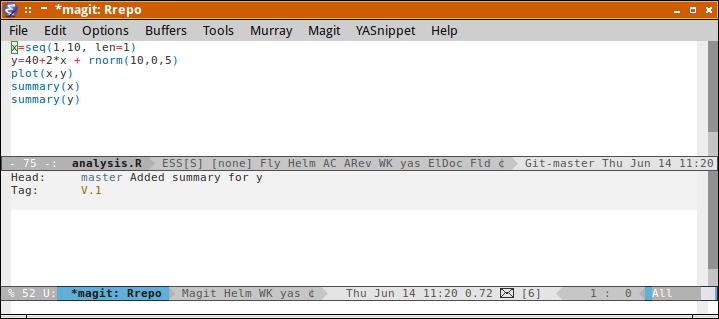
Notice now that the magit window has a Tag listing.
Rolling back to previous commits
For the purpose of this demonstration, we will generate three new copies of the Rrepo. This will ensure that for each of the three rolling back options, we can start with the same history. So I will create RrepoA, RrepoB, RrepoC that are exact copies of Rrepo. This can be done by copying the Rrepo folder three times...
cp -R ~/tmp/Rrepo ~/tmp/RrepoA cp -R ~/tmp/Rrepo ~/tmp/RrepoB cp -R ~/tmp/Rrepo ~/tmp/RrepoC
Reset
Resetting moves the HEAD to the nominated commit.
We will be working with RrepoA.
As far as I know, there is no way to add tags directly from the RStudio GUI. It can be performed from the pure git commands in a shell however.
From the Git panel, click the cog icon and select Shell from the dropdown menu.
A terminal window will appear into which you can enter the following:
cd ~/tmp/RrepoA git reset --hard 428a2
HEAD is now at 428a27f Added summary for x
If you then revisit the History or Diff and click the refresh button (circular arrow), you will notice that the third commit is absent and HEAD is back on the second commit.
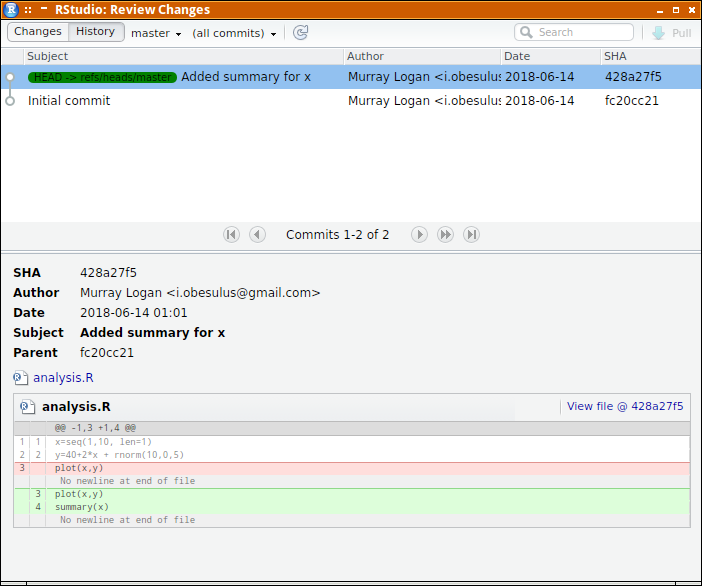
You can then close any lingering windows (not the main RStudio window obviously).
From the magit status (C-x g), put the cursor on a commit (HEAD) and enter the letter 'X' followed by 'h' (for hard reset).
When prompted, provide a name for the tag or commit. In this case we will use 428a2.
With RETURN again to place the tag on master (the default).
The reset can be confirmed by exploring the log or reflog
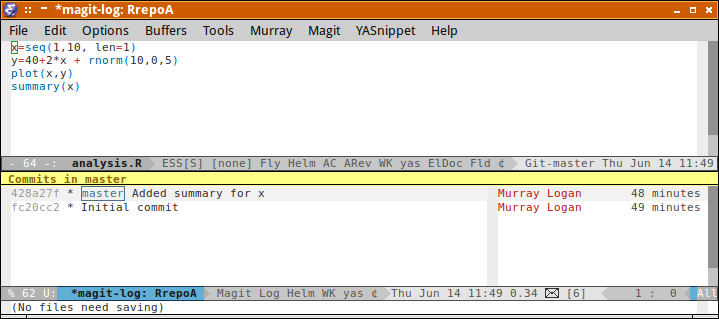
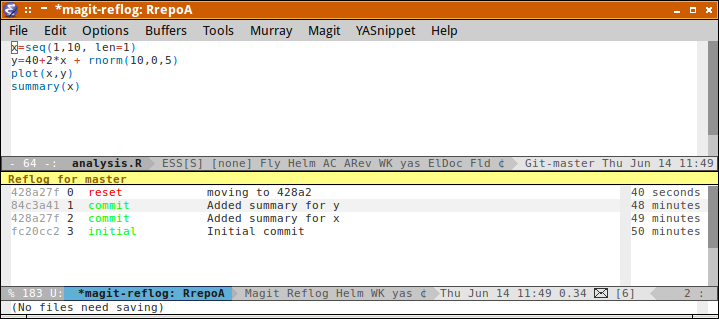
Revert
Reverting reverses the past commit(s) so as to rollback to a previous state. It does so by adding a new commit that undoes the previous changes.
We will be working with RrepoB.
As far as I know, there is no way to add tags directly from the RStudio GUI. It can be performed from the pure git commands in a shell however.
From the Git panel, click the cog icon and select Shell from the dropdown menu.
A terminal window will appear into which you can enter the following:
cd ~/tmp/RrepoB git revert HEAD
[master e766804] Revert "Added summary for y" 1 file changed, 1 insertion(+), 2 deletions(-)
If you then revisit the History or Diff and click the refresh button (circular arrow), you will notice that the third commit is absent and HEAD is back on the second commit.
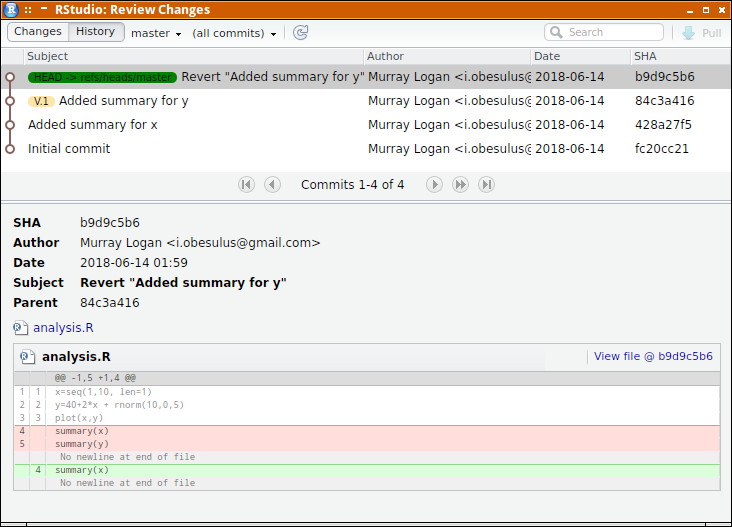
You can then close any lingering windows (not the main RStudio window obviously).
From the magit status (C-x g), put the cursor on a commit (HEAD) and enter the letter 'X' followed by 'h' (for hard revert).
When prompted, provide a name for the tag or commit. In this case we will use 428a2.
With RETURN again to place the tag on master (the default).
The revert can be confirmed by exploring the log or reflog
And the reflog..
Checkout
Checking out allows you to review the state of the code at a particular commit.
We will be working with RrepoC.
As far as I know, there is no way to add tags directly from the RStudio GUI. It can be performed from the pure git commands in a shell however.
From the Git panel, click the cog icon and select Shell from the dropdown menu.
A terminal window will appear into which you can enter the following:
cd ~/tmp/RrepoC git checkout 428a2
Note: checking out '428a2'. You are in 'detached HEAD' state. You can look around, make experimental changes and commit them, and you can discard any commits you make in this state without impacting any branches by performing another checkout. If you want to create a new branch to retain commits you create, you may do so (now or later) by using -b with the checkout command again. Example: git checkout -b <new-branch-name> HEAD is now at 428a27f... Added summary for x
If you then revisit the History or Diff and click the refresh button (circular arrow), you will notice that the third commit is absent and HEAD is back on the second commit.
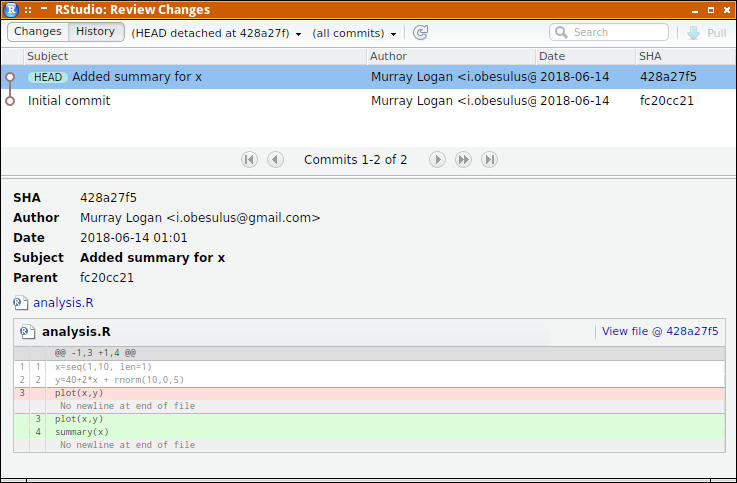
You can then close any lingering windows (not the main RStudio window obviously).
From the magit status (C-x g), put the cursor on a commit (HEAD) and enter the letter 'b' followed by 'b'.
When prompted, provide a name for the tag or commit. In this case we will use 428a2.
With RETURN again the default.
The checkout can be confirmed by exploring the log or reflog
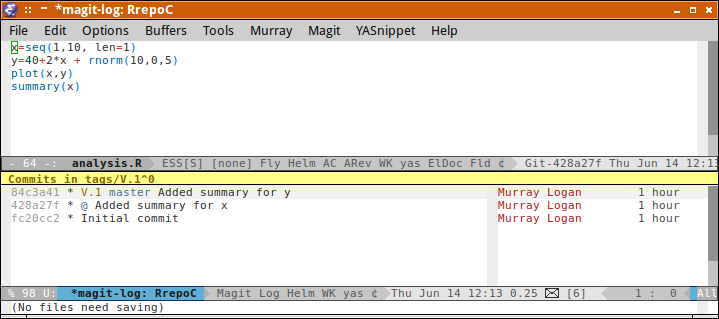
And the reflog..
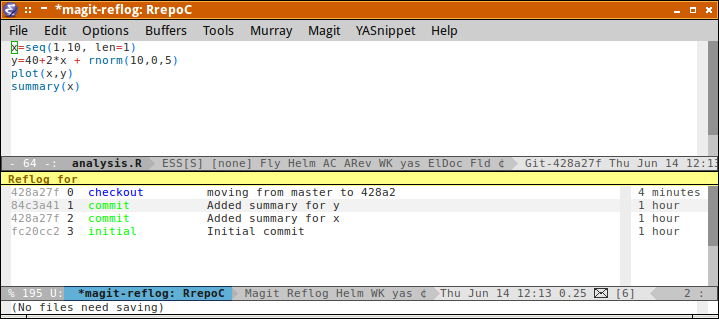
Branching
For this demonstration, we will work on a copy of Rrepo. Lets call the copy Rrepo1.
cp -R ~/tmp/Rrepo ~/tmp/Rrepo1
In this demonstration,
- we will start a new branch (which we will call 'Experimental')
- add and commit a change
As far as I know, there is no way to add tags directly from the RStudio GUI. It can be performed from the pure git commands in a shell however.
From the Git panel, click the cog icon and select Shell from the dropdown menu.
A terminal window will appear into which you can enter the following:
cd ~/tmp/Rrepo1 git checkout -b Experimental
Switched to a new branch 'Experimental'
If you then revisit the History or Diff and click the refresh button (circular arrow) followed by the branch dropdown (initially this will say master with a small arrow head), you will notice that Experimental has been added to the list of branches.
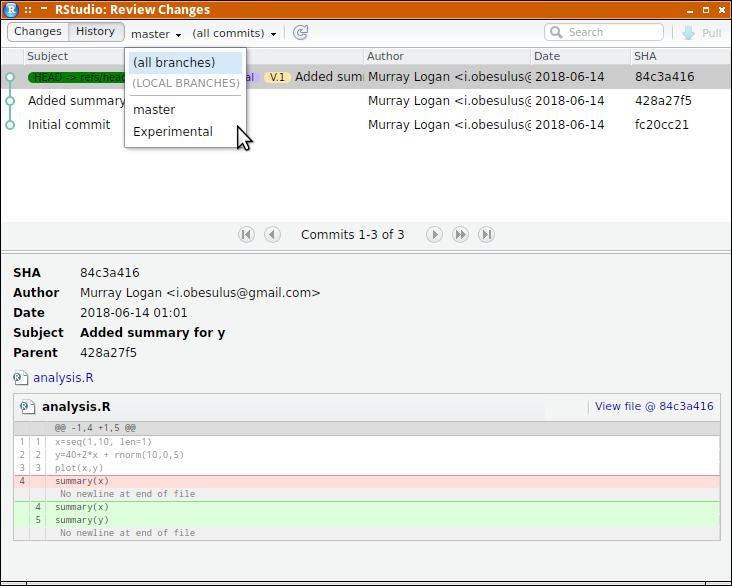
You can then close any lingering windows (not the main RStudio window obviously).
Now if we make, add and commit a change (in this case add mean(x) to the end of the file)...

Lets return to the master branch. This is done by clicking on the branch dropdown from the Git tab

You will notice that the analysis.R file is altered to the state it had been in the master branch.
We will now modify the analysis.R file and commit the changes (this time adding mean(y) to
the end of the file.

If we now explore the history and in particular, select (all branches) from the branch dropdown,
we will see the relationship between the different branches.

From the magit status (C-x g), put the cursor on a commit (HEAD) and enter the letter 'b' followed by 'c' (to create and checkout a new branch).
- when prompted, provide a name where to start this branch (default master is fine).
- then provide a name for the new branch (I decided Experimental in this case!)
The branch can be confirmed by exploring the log
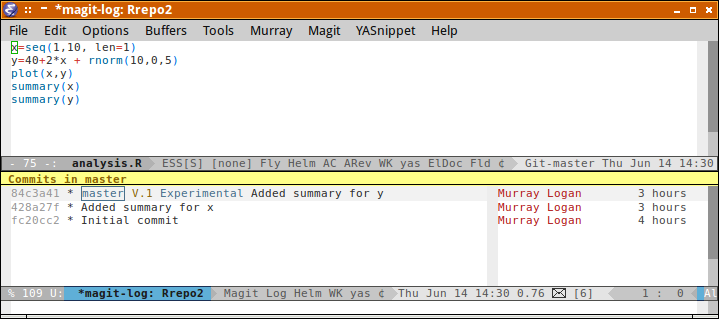
And the reflog..
Now if we make, add and commit a change such as the following (see last line of the file):

and then review the log and reflog..
Now lets return to the master branch by
entering 'b' followed by 'b' and then selecting or entering master.
Having switched to the master branch, make and commit another change (add mean(y)
to the end of the file. Finally, examine the logs of all branches ('b' followed by 'a') to explore the relationship between branches.
